What’s new in 0.23.0 (May 15, 2018)¶
This is a major release from 0.22.0 and includes a number of API changes, deprecations, new features, enhancements, and performance improvements along with a large number of bug fixes. We recommend that all users upgrade to this version.
Highlights include:
Check the API Changes and deprecations before updating.
Warning
Starting January 1, 2019, pandas feature releases will support Python 3 only. See Dropping Python 2.7 for more.
What’s new in v0.23.0
New features¶
JSON read/write round-trippable with orient='table'¶
A DataFrame can now be written to and subsequently read back via JSON while preserving metadata through usage of the orient='table' argument (see GH18912 and GH9146). Previously, none of the available orient values guaranteed the preservation of dtypes and index names, amongst other metadata.
In [1]: df = pd.DataFrame({'foo': [1, 2, 3, 4],
...: 'bar': ['a', 'b', 'c', 'd'],
...: 'baz': pd.date_range('2018-01-01', freq='d', periods=4),
...: 'qux': pd.Categorical(['a', 'b', 'c', 'c'])},
...: index=pd.Index(range(4), name='idx'))
...:
In [2]: df
Out[2]:
foo bar baz qux
idx
0 1 a 2018-01-01 a
1 2 b 2018-01-02 b
2 3 c 2018-01-03 c
3 4 d 2018-01-04 c
[4 rows x 4 columns]
In [3]: df.dtypes
Out[3]:
foo int64
bar object
baz datetime64[ns]
qux category
Length: 4, dtype: object
In [4]: df.to_json('test.json', orient='table')
In [5]: new_df = pd.read_json('test.json', orient='table')
In [6]: new_df
Out[6]:
foo bar baz qux
idx
0 1 a 2018-01-01 a
1 2 b 2018-01-02 b
2 3 c 2018-01-03 c
3 4 d 2018-01-04 c
[4 rows x 4 columns]
In [7]: new_df.dtypes
Out[7]:
foo int64
bar object
baz datetime64[ns]
qux category
Length: 4, dtype: object
Please note that the string index is not supported with the round trip format, as it is used by default in write_json to indicate a missing index name.
In [8]: df.index.name = 'index'
In [9]: df.to_json('test.json', orient='table')
In [10]: new_df = pd.read_json('test.json', orient='table')
In [11]: new_df
Out[11]:
foo bar baz qux
0 1 a 2018-01-01 a
1 2 b 2018-01-02 b
2 3 c 2018-01-03 c
3 4 d 2018-01-04 c
[4 rows x 4 columns]
In [12]: new_df.dtypes
Out[12]:
foo int64
bar object
baz datetime64[ns]
qux category
Length: 4, dtype: object
Method .assign() accepts dependent arguments¶
The DataFrame.assign() now accepts dependent keyword arguments for python version later than 3.6 (see also PEP 468). Later keyword arguments may now refer to earlier ones if the argument is a callable. See the
documentation here (GH14207)
In [13]: df = pd.DataFrame({'A': [1, 2, 3]})
In [14]: df
Out[14]:
A
0 1
1 2
2 3
[3 rows x 1 columns]
In [15]: df.assign(B=df.A, C=lambda x: x['A'] + x['B'])
Out[15]:
A B C
0 1 1 2
1 2 2 4
2 3 3 6
[3 rows x 3 columns]
Warning
This may subtly change the behavior of your code when you’re
using .assign() to update an existing column. Previously, callables
referring to other variables being updated would get the “old” values
Previous behavior:
In [2]: df = pd.DataFrame({"A": [1, 2, 3]})
In [3]: df.assign(A=lambda df: df.A + 1, C=lambda df: df.A * -1)
Out[3]:
A C
0 2 -1
1 3 -2
2 4 -3
New behavior:
In [16]: df.assign(A=df.A + 1, C=lambda df: df.A * -1)
Out[16]:
A C
0 2 -2
1 3 -3
2 4 -4
[3 rows x 2 columns]
Merging on a combination of columns and index levels¶
Strings passed to DataFrame.merge() as the on, left_on, and right_on
parameters may now refer to either column names or index level names.
This enables merging DataFrame instances on a combination of index levels
and columns without resetting indexes. See the Merge on columns and
levels documentation section.
(GH14355)
In [17]: left_index = pd.Index(['K0', 'K0', 'K1', 'K2'], name='key1')
In [18]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key2': ['K0', 'K1', 'K0', 'K1']},
....: index=left_index)
....:
In [19]: right_index = pd.Index(['K0', 'K1', 'K2', 'K2'], name='key1')
In [20]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3'],
....: 'key2': ['K0', 'K0', 'K0', 'K1']},
....: index=right_index)
....:
In [21]: left.merge(right, on=['key1', 'key2'])
Out[21]:
A B key2 C D
key1
K0 A0 B0 K0 C0 D0
K1 A2 B2 K0 C1 D1
K2 A3 B3 K1 C3 D3
[3 rows x 5 columns]
Sorting by a combination of columns and index levels¶
Strings passed to DataFrame.sort_values() as the by parameter may
now refer to either column names or index level names. This enables sorting
DataFrame instances by a combination of index levels and columns without
resetting indexes. See the Sorting by Indexes and Values documentation section.
(GH14353)
# Build MultiIndex
In [22]: idx = pd.MultiIndex.from_tuples([('a', 1), ('a', 2), ('a', 2),
....: ('b', 2), ('b', 1), ('b', 1)])
....:
In [23]: idx.names = ['first', 'second']
# Build DataFrame
In [24]: df_multi = pd.DataFrame({'A': np.arange(6, 0, -1)},
....: index=idx)
....:
In [25]: df_multi
Out[25]:
A
first second
a 1 6
2 5
2 4
b 2 3
1 2
1 1
[6 rows x 1 columns]
# Sort by 'second' (index) and 'A' (column)
In [26]: df_multi.sort_values(by=['second', 'A'])
Out[26]:
A
first second
b 1 1
1 2
a 1 6
b 2 3
a 2 4
2 5
[6 rows x 1 columns]
Extending pandas with custom types (experimental)¶
pandas now supports storing array-like objects that aren’t necessarily 1-D NumPy arrays as columns in a DataFrame or values in a Series. This allows third-party libraries to implement extensions to NumPy’s types, similar to how pandas implemented categoricals, datetimes with timezones, periods, and intervals.
As a demonstration, we’ll use cyberpandas, which provides an IPArray type
for storing ip addresses.
In [1]: from cyberpandas import IPArray
In [2]: values = IPArray([
...: 0,
...: 3232235777,
...: 42540766452641154071740215577757643572
...: ])
...:
...:
IPArray isn’t a normal 1-D NumPy array, but because it’s a pandas
ExtensionArray, it can be stored properly inside pandas’ containers.
In [3]: ser = pd.Series(values)
In [4]: ser
Out[4]:
0 0.0.0.0
1 192.168.1.1
2 2001:db8:85a3::8a2e:370:7334
dtype: ip
Notice that the dtype is ip. The missing value semantics of the underlying
array are respected:
In [5]: ser.isna()
Out[5]:
0 True
1 False
2 False
dtype: bool
For more, see the extension types documentation. If you build an extension array, publicize it on our ecosystem page.
New observed keyword for excluding unobserved categories in GroupBy¶
Grouping by a categorical includes the unobserved categories in the output.
When grouping by multiple categorical columns, this means you get the cartesian product of all the
categories, including combinations where there are no observations, which can result in a large
number of groups. We have added a keyword observed to control this behavior, it defaults to
observed=False for backward-compatibility. (GH14942, GH8138, GH15217, GH17594, GH8669, GH20583, GH20902)
In [27]: cat1 = pd.Categorical(["a", "a", "b", "b"],
....: categories=["a", "b", "z"], ordered=True)
....:
In [28]: cat2 = pd.Categorical(["c", "d", "c", "d"],
....: categories=["c", "d", "y"], ordered=True)
....:
In [29]: df = pd.DataFrame({"A": cat1, "B": cat2, "values": [1, 2, 3, 4]})
In [30]: df['C'] = ['foo', 'bar'] * 2
In [31]: df
Out[31]:
A B values C
0 a c 1 foo
1 a d 2 bar
2 b c 3 foo
3 b d 4 bar
[4 rows x 4 columns]
To show all values, the previous behavior:
In [32]: df.groupby(['A', 'B', 'C'], observed=False).count()
Out[32]:
values
A B C
a c bar 0
foo 1
d bar 1
foo 0
y bar 0
... ...
z c foo 0
d bar 0
foo 0
y bar 0
foo 0
[18 rows x 1 columns]
To show only observed values:
In [33]: df.groupby(['A', 'B', 'C'], observed=True).count()
Out[33]:
values
A B C
a c foo 1
d bar 1
b c foo 1
d bar 1
[4 rows x 1 columns]
For pivoting operations, this behavior is already controlled by the dropna keyword:
In [34]: cat1 = pd.Categorical(["a", "a", "b", "b"],
....: categories=["a", "b", "z"], ordered=True)
....:
In [35]: cat2 = pd.Categorical(["c", "d", "c", "d"],
....: categories=["c", "d", "y"], ordered=True)
....:
In [36]: df = pd.DataFrame({"A": cat1, "B": cat2, "values": [1, 2, 3, 4]})
In [37]: df
Out[37]:
A B values
0 a c 1
1 a d 2
2 b c 3
3 b d 4
[4 rows x 3 columns]
In [38]: pd.pivot_table(df, values='values', index=['A', 'B'],
....: dropna=True)
....:
Out[38]:
values
A B
a c 1
d 2
b c 3
d 4
[4 rows x 1 columns]
In [39]: pd.pivot_table(df, values='values', index=['A', 'B'],
....: dropna=False)
....:
Out[39]:
values
A B
a c 1.0
d 2.0
y NaN
b c 3.0
d 4.0
y NaN
z c NaN
d NaN
y NaN
[9 rows x 1 columns]
Rolling/Expanding.apply() accepts raw=False to pass a Series to the function¶
Series.rolling().apply(), DataFrame.rolling().apply(),
Series.expanding().apply(), and DataFrame.expanding().apply() have gained a raw=None parameter.
This is similar to DataFame.apply(). This parameter, if True allows one to send a np.ndarray to the applied function. If False a Series will be passed. The
default is None, which preserves backward compatibility, so this will default to True, sending an np.ndarray.
In a future version the default will be changed to False, sending a Series. (GH5071, GH20584)
In [40]: s = pd.Series(np.arange(5), np.arange(5) + 1)
In [41]: s
Out[41]:
1 0
2 1
3 2
4 3
5 4
Length: 5, dtype: int64
Pass a Series:
In [42]: s.rolling(2, min_periods=1).apply(lambda x: x.iloc[-1], raw=False)
Out[42]:
1 0.0
2 1.0
3 2.0
4 3.0
5 4.0
Length: 5, dtype: float64
Mimic the original behavior of passing a ndarray:
In [43]: s.rolling(2, min_periods=1).apply(lambda x: x[-1], raw=True)
Out[43]:
1 0.0
2 1.0
3 2.0
4 3.0
5 4.0
Length: 5, dtype: float64
DataFrame.interpolate has gained the limit_area kwarg¶
DataFrame.interpolate() has gained a limit_area parameter to allow further control of which NaN s are replaced.
Use limit_area='inside' to fill only NaNs surrounded by valid values or use limit_area='outside' to fill only NaN s
outside the existing valid values while preserving those inside. (GH16284) See the full documentation here.
In [44]: ser = pd.Series([np.nan, np.nan, 5, np.nan, np.nan,
....: np.nan, 13, np.nan, np.nan])
....:
In [45]: ser
Out[45]:
0 NaN
1 NaN
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
Length: 9, dtype: float64
Fill one consecutive inside value in both directions
In [46]: ser.interpolate(limit_direction='both', limit_area='inside', limit=1)
Out[46]:
0 NaN
1 NaN
2 5.0
3 7.0
4 NaN
5 11.0
6 13.0
7 NaN
8 NaN
Length: 9, dtype: float64
Fill all consecutive outside values backward
In [47]: ser.interpolate(limit_direction='backward', limit_area='outside')
Out[47]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 NaN
8 NaN
Length: 9, dtype: float64
Fill all consecutive outside values in both directions
In [48]: ser.interpolate(limit_direction='both', limit_area='outside')
Out[48]:
0 5.0
1 5.0
2 5.0
3 NaN
4 NaN
5 NaN
6 13.0
7 13.0
8 13.0
Length: 9, dtype: float64
Function get_dummies now supports dtype argument¶
The get_dummies() now accepts a dtype argument, which specifies a dtype for the new columns. The default remains uint8. (GH18330)
In [49]: df = pd.DataFrame({'a': [1, 2], 'b': [3, 4], 'c': [5, 6]})
In [50]: pd.get_dummies(df, columns=['c']).dtypes
Out[50]:
a int64
b int64
c_5 uint8
c_6 uint8
Length: 4, dtype: object
In [51]: pd.get_dummies(df, columns=['c'], dtype=bool).dtypes
Out[51]:
a int64
b int64
c_5 bool
c_6 bool
Length: 4, dtype: object
Timedelta mod method¶
mod (%) and divmod operations are now defined on Timedelta objects
when operating with either timedelta-like or with numeric arguments.
See the documentation here. (GH19365)
In [52]: td = pd.Timedelta(hours=37)
In [53]: td % pd.Timedelta(minutes=45)
Out[53]: Timedelta('0 days 00:15:00')
Method .rank() handles inf values when NaN are present¶
In previous versions, .rank() would assign inf elements NaN as their ranks. Now ranks are calculated properly. (GH6945)
In [54]: s = pd.Series([-np.inf, 0, 1, np.nan, np.inf])
In [55]: s
Out[55]:
0 -inf
1 0.0
2 1.0
3 NaN
4 inf
Length: 5, dtype: float64
Previous behavior:
In [11]: s.rank()
Out[11]:
0 1.0
1 2.0
2 3.0
3 NaN
4 NaN
dtype: float64
Current behavior:
In [56]: s.rank()
Out[56]:
0 1.0
1 2.0
2 3.0
3 NaN
4 4.0
Length: 5, dtype: float64
Furthermore, previously if you rank inf or -inf values together with NaN values, the calculation won’t distinguish NaN from infinity when using ‘top’ or ‘bottom’ argument.
In [57]: s = pd.Series([np.nan, np.nan, -np.inf, -np.inf])
In [58]: s
Out[58]:
0 NaN
1 NaN
2 -inf
3 -inf
Length: 4, dtype: float64
Previous behavior:
In [15]: s.rank(na_option='top')
Out[15]:
0 2.5
1 2.5
2 2.5
3 2.5
dtype: float64
Current behavior:
In [59]: s.rank(na_option='top')
Out[59]:
0 1.5
1 1.5
2 3.5
3 3.5
Length: 4, dtype: float64
These bugs were squashed:
Bug in
DataFrame.rank()andSeries.rank()whenmethod='dense'andpct=Truein which percentile ranks were not being used with the number of distinct observations (GH15630)Bug in
Series.rank()andDataFrame.rank()whenascending='False'failed to return correct ranks for infinity ifNaNwere present (GH19538)Bug in
DataFrameGroupBy.rank()where ranks were incorrect when both infinity andNaNwere present (GH20561)
Series.str.cat has gained the join kwarg¶
Previously, Series.str.cat() did not – in contrast to most of pandas – align Series on their index before concatenation (see GH18657).
The method has now gained a keyword join to control the manner of alignment, see examples below and here.
In v.0.23 join will default to None (meaning no alignment), but this default will change to 'left' in a future version of pandas.
In [60]: s = pd.Series(['a', 'b', 'c', 'd'])
In [61]: t = pd.Series(['b', 'd', 'e', 'c'], index=[1, 3, 4, 2])
In [62]: s.str.cat(t)
Out[62]:
0 NaN
1 bb
2 cc
3 dd
Length: 4, dtype: object
In [63]: s.str.cat(t, join='left', na_rep='-')
Out[63]:
0 a-
1 bb
2 cc
3 dd
Length: 4, dtype: object
Furthermore, Series.str.cat() now works for CategoricalIndex as well (previously raised a ValueError; see GH20842).
DataFrame.astype performs column-wise conversion to Categorical¶
DataFrame.astype() can now perform column-wise conversion to Categorical by supplying the string 'category' or
a CategoricalDtype. Previously, attempting this would raise a NotImplementedError. See the
Object creation section of the documentation for more details and examples. (GH12860, GH18099)
Supplying the string 'category' performs column-wise conversion, with only labels appearing in a given column set as categories:
In [64]: df = pd.DataFrame({'A': list('abca'), 'B': list('bccd')})
In [65]: df = df.astype('category')
In [66]: df['A'].dtype
Out[66]: CategoricalDtype(categories=['a', 'b', 'c'], ordered=False)
In [67]: df['B'].dtype
Out[67]: CategoricalDtype(categories=['b', 'c', 'd'], ordered=False)
Supplying a CategoricalDtype will make the categories in each column consistent with the supplied dtype:
In [68]: from pandas.api.types import CategoricalDtype
In [69]: df = pd.DataFrame({'A': list('abca'), 'B': list('bccd')})
In [70]: cdt = CategoricalDtype(categories=list('abcd'), ordered=True)
In [71]: df = df.astype(cdt)
In [72]: df['A'].dtype
Out[72]: CategoricalDtype(categories=['a', 'b', 'c', 'd'], ordered=True)
In [73]: df['B'].dtype
Out[73]: CategoricalDtype(categories=['a', 'b', 'c', 'd'], ordered=True)
Other enhancements¶
Unary
+now permitted forSeriesandDataFrameas numeric operator (GH16073)Better support for
to_excel()output with thexlsxwriterengine. (GH16149)pandas.tseries.frequencies.to_offset()now accepts leading ‘+’ signs e.g. ‘+1h’. (GH18171)MultiIndex.unique()now supports thelevel=argument, to get unique values from a specific index level (GH17896)pandas.io.formats.style.Stylernow has methodhide_index()to determine whether the index will be rendered in output (GH14194)pandas.io.formats.style.Stylernow has methodhide_columns()to determine whether columns will be hidden in output (GH14194)Improved wording of
ValueErrorraised into_datetime()whenunit=is passed with a non-convertible value (GH14350)Series.fillna()now accepts a Series or a dict as avaluefor a categorical dtype (GH17033)pandas.read_clipboard()updated to use qtpy, falling back to PyQt5 and then PyQt4, adding compatibility with Python3 and multiple python-qt bindings (GH17722)Improved wording of
ValueErrorraised inread_csv()when theusecolsargument cannot match all columns. (GH17301)DataFrame.corrwith()now silently drops non-numeric columns when passed a Series. Before, an exception was raised (GH18570).IntervalIndexnow supports time zone awareIntervalobjects (GH18537, GH18538)Series()/DataFrame()tab completion also returns identifiers in the first level of aMultiIndex(). (GH16326)read_excel()has gained thenrowsparameter (GH16645)DataFrame.append()can now in more cases preserve the type of the calling dataframe’s columns (e.g. if both areCategoricalIndex) (GH18359)DataFrame.to_json()andSeries.to_json()now accept anindexargument which allows the user to exclude the index from the JSON output (GH17394)IntervalIndex.to_tuples()has gained thena_tupleparameter to control whether NA is returned as a tuple of NA, or NA itself (GH18756)Categorical.rename_categories,CategoricalIndex.rename_categoriesandSeries.cat.rename_categoriescan now take a callable as their argument (GH18862)IntervalandIntervalIndexhave gained alengthattribute (GH18789)Resamplerobjects now have a functioningpipemethod. Previously, calls topipewere diverted to themeanmethod (GH17905).is_scalar()now returnsTrueforDateOffsetobjects (GH18943).DataFrame.pivot()now accepts a list for thevalues=kwarg (GH17160).Added
pandas.api.extensions.register_dataframe_accessor(),pandas.api.extensions.register_series_accessor(), andpandas.api.extensions.register_index_accessor(), accessor for libraries downstream of pandas to register custom accessors like.caton pandas objects. See Registering Custom Accessors for more (GH14781).IntervalIndex.astypenow supports conversions between subtypes when passed anIntervalDtype(GH19197)IntervalIndexand its associated constructor methods (from_arrays,from_breaks,from_tuples) have gained adtypeparameter (GH19262)Added
pandas.core.groupby.SeriesGroupBy.is_monotonic_increasing()andpandas.core.groupby.SeriesGroupBy.is_monotonic_decreasing()(GH17015)For subclassed
DataFrames,DataFrame.apply()will now preserve theSeriessubclass (if defined) when passing the data to the applied function (GH19822)DataFrame.from_dict()now accepts acolumnsargument that can be used to specify the column names whenorient='index'is used (GH18529)Added option
display.html.use_mathjaxso MathJax can be disabled when rendering tables inJupyternotebooks (GH19856, GH19824)DataFrame.replace()now supports themethodparameter, which can be used to specify the replacement method whento_replaceis a scalar, list or tuple andvalueisNone(GH19632)Timestamp.month_name(),DatetimeIndex.month_name(), andSeries.dt.month_name()are now available (GH12805)Timestamp.day_name()andDatetimeIndex.day_name()are now available to return day names with a specified locale (GH12806)DataFrame.to_sql()now performs a multi-value insert if the underlying connection supports itk rather than inserting row by row.SQLAlchemydialects supporting multi-value inserts include:mysql,postgresql,sqliteand any dialect withsupports_multivalues_insert. (GH14315, GH8953)read_html()now accepts adisplayed_onlykeyword argument to controls whether or not hidden elements are parsed (Trueby default) (GH20027)read_html()now reads all<tbody>elements in a<table>, not just the first. (GH20690)quantile()andquantile()now accept theinterpolationkeyword,linearby default (GH20497)zip compression is supported via
compression=zipinDataFrame.to_pickle(),Series.to_pickle(),DataFrame.to_csv(),Series.to_csv(),DataFrame.to_json(),Series.to_json(). (GH17778)WeekOfMonthconstructor now supportsn=0(GH20517).DataFrameandSeriesnow support matrix multiplication (@) operator (GH10259) for Python>=3.5Updated
DataFrame.to_gbq()andpandas.read_gbq()signature and documentation to reflect changes from the pandas-gbq library version 0.4.0. Adds intersphinx mapping to pandas-gbq library. (GH20564)Added new writer for exporting Stata dta files in version 117,
StataWriter117. This format supports exporting strings with lengths up to 2,000,000 characters (GH16450)to_hdf()andread_hdf()now accept anerrorskeyword argument to control encoding error handling (GH20835)cut()has gained theduplicates='raise'|'drop'option to control whether to raise on duplicated edges (GH20947)date_range(),timedelta_range(), andinterval_range()now return a linearly spaced index ifstart,stop, andperiodsare specified, butfreqis not. (GH20808, GH20983, GH20976)
Backwards incompatible API changes¶
Dependencies have increased minimum versions¶
We have updated our minimum supported versions of dependencies (GH15184). If installed, we now require:
Package |
Minimum Version |
Required |
Issue |
|---|---|---|---|
python-dateutil |
2.5.0 |
X |
|
openpyxl |
2.4.0 |
||
beautifulsoup4 |
4.2.1 |
||
setuptools |
24.2.0 |
Instantiation from dicts preserves dict insertion order for Python 3.6+¶
Until Python 3.6, dicts in Python had no formally defined ordering. For Python
version 3.6 and later, dicts are ordered by insertion order, see
PEP 468.
pandas will use the dict’s insertion order, when creating a Series or
DataFrame from a dict and you’re using Python version 3.6 or
higher. (GH19884)
Previous behavior (and current behavior if on Python < 3.6):
In [16]: pd.Series({'Income': 2000,
....: 'Expenses': -1500,
....: 'Taxes': -200,
....: 'Net result': 300})
Out[16]:
Expenses -1500
Income 2000
Net result 300
Taxes -200
dtype: int64
Note the Series above is ordered alphabetically by the index values.
New behavior (for Python >= 3.6):
In [74]: pd.Series({'Income': 2000,
....: 'Expenses': -1500,
....: 'Taxes': -200,
....: 'Net result': 300})
....:
Out[74]:
Income 2000
Expenses -1500
Taxes -200
Net result 300
Length: 4, dtype: int64
Notice that the Series is now ordered by insertion order. This new behavior is
used for all relevant pandas types (Series, DataFrame, SparseSeries
and SparseDataFrame).
If you wish to retain the old behavior while using Python >= 3.6, you can use
.sort_index():
In [75]: pd.Series({'Income': 2000,
....: 'Expenses': -1500,
....: 'Taxes': -200,
....: 'Net result': 300}).sort_index()
....:
Out[75]:
Expenses -1500
Income 2000
Net result 300
Taxes -200
Length: 4, dtype: int64
Deprecate Panel¶
Panel was deprecated in the 0.20.x release, showing as a DeprecationWarning. Using Panel will now show a FutureWarning. The recommended way to represent 3-D data are
with a MultiIndex on a DataFrame via the to_frame() or with the xarray package. pandas
provides a to_xarray() method to automate this conversion (GH13563, GH18324).
In [75]: import pandas._testing as tm
In [76]: p = tm.makePanel()
In [77]: p
Out[77]:
<class 'pandas.core.panel.Panel'>
Dimensions: 3 (items) x 3 (major_axis) x 4 (minor_axis)
Items axis: ItemA to ItemC
Major_axis axis: 2000-01-03 00:00:00 to 2000-01-05 00:00:00
Minor_axis axis: A to D
Convert to a MultiIndex DataFrame
In [78]: p.to_frame()
Out[78]:
ItemA ItemB ItemC
major minor
2000-01-03 A 0.469112 0.721555 0.404705
B -1.135632 0.271860 -1.039268
C 0.119209 0.276232 -1.344312
D -2.104569 0.113648 -0.109050
2000-01-04 A -0.282863 -0.706771 0.577046
B 1.212112 -0.424972 -0.370647
C -1.044236 -1.087401 0.844885
D -0.494929 -1.478427 1.643563
2000-01-05 A -1.509059 -1.039575 -1.715002
B -0.173215 0.567020 -1.157892
C -0.861849 -0.673690 1.075770
D 1.071804 0.524988 -1.469388
[12 rows x 3 columns]
Convert to an xarray DataArray
In [79]: p.to_xarray()
Out[79]:
<xarray.DataArray (items: 3, major_axis: 3, minor_axis: 4)>
array([[[ 0.469112, -1.135632, 0.119209, -2.104569],
[-0.282863, 1.212112, -1.044236, -0.494929],
[-1.509059, -0.173215, -0.861849, 1.071804]],
[[ 0.721555, 0.27186 , 0.276232, 0.113648],
[-0.706771, -0.424972, -1.087401, -1.478427],
[-1.039575, 0.56702 , -0.67369 , 0.524988]],
[[ 0.404705, -1.039268, -1.344312, -0.10905 ],
[ 0.577046, -0.370647, 0.844885, 1.643563],
[-1.715002, -1.157892, 1.07577 , -1.469388]]])
Coordinates:
* items (items) object 'ItemA' 'ItemB' 'ItemC'
* major_axis (major_axis) datetime64[ns] 2000-01-03 2000-01-04 2000-01-05
* minor_axis (minor_axis) object 'A' 'B' 'C' 'D'
pandas.core.common removals¶
The following error & warning messages are removed from pandas.core.common (GH13634, GH19769):
PerformanceWarningUnsupportedFunctionCallUnsortedIndexErrorAbstractMethodError
These are available from import from pandas.errors (since 0.19.0).
Changes to make output of DataFrame.apply consistent¶
DataFrame.apply() was inconsistent when applying an arbitrary user-defined-function that returned a list-like with axis=1. Several bugs and inconsistencies
are resolved. If the applied function returns a Series, then pandas will return a DataFrame; otherwise a Series will be returned, this includes the case
where a list-like (e.g. tuple or list is returned) (GH16353, GH17437, GH17970, GH17348, GH17892, GH18573,
GH17602, GH18775, GH18901, GH18919).
In [76]: df = pd.DataFrame(np.tile(np.arange(3), 6).reshape(6, -1) + 1,
....: columns=['A', 'B', 'C'])
....:
In [77]: df
Out[77]:
A B C
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
Previous behavior: if the returned shape happened to match the length of original columns, this would return a DataFrame.
If the return shape did not match, a Series with lists was returned.
In [3]: df.apply(lambda x: [1, 2, 3], axis=1)
Out[3]:
A B C
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
In [4]: df.apply(lambda x: [1, 2], axis=1)
Out[4]:
0 [1, 2]
1 [1, 2]
2 [1, 2]
3 [1, 2]
4 [1, 2]
5 [1, 2]
dtype: object
New behavior: When the applied function returns a list-like, this will now always return a Series.
In [78]: df.apply(lambda x: [1, 2, 3], axis=1)
Out[78]:
0 [1, 2, 3]
1 [1, 2, 3]
2 [1, 2, 3]
3 [1, 2, 3]
4 [1, 2, 3]
5 [1, 2, 3]
Length: 6, dtype: object
In [79]: df.apply(lambda x: [1, 2], axis=1)
Out[79]:
0 [1, 2]
1 [1, 2]
2 [1, 2]
3 [1, 2]
4 [1, 2]
5 [1, 2]
Length: 6, dtype: object
To have expanded columns, you can use result_type='expand'
In [80]: df.apply(lambda x: [1, 2, 3], axis=1, result_type='expand')
Out[80]:
0 1 2
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
To broadcast the result across the original columns (the old behaviour for
list-likes of the correct length), you can use result_type='broadcast'.
The shape must match the original columns.
In [81]: df.apply(lambda x: [1, 2, 3], axis=1, result_type='broadcast')
Out[81]:
A B C
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
Returning a Series allows one to control the exact return structure and column names:
In [82]: df.apply(lambda x: pd.Series([1, 2, 3], index=['D', 'E', 'F']), axis=1)
Out[82]:
D E F
0 1 2 3
1 1 2 3
2 1 2 3
3 1 2 3
4 1 2 3
5 1 2 3
[6 rows x 3 columns]
Concatenation will no longer sort¶
In a future version of pandas pandas.concat() will no longer sort the non-concatenation axis when it is not already aligned.
The current behavior is the same as the previous (sorting), but now a warning is issued when sort is not specified and the non-concatenation axis is not aligned (GH4588).
In [83]: df1 = pd.DataFrame({"a": [1, 2], "b": [1, 2]}, columns=['b', 'a'])
In [84]: df2 = pd.DataFrame({"a": [4, 5]})
In [85]: pd.concat([df1, df2])
Out[85]:
b a
0 1.0 1
1 2.0 2
0 NaN 4
1 NaN 5
[4 rows x 2 columns]
To keep the previous behavior (sorting) and silence the warning, pass sort=True
In [86]: pd.concat([df1, df2], sort=True)
Out[86]:
a b
0 1 1.0
1 2 2.0
0 4 NaN
1 5 NaN
[4 rows x 2 columns]
To accept the future behavior (no sorting), pass sort=False
Note that this change also applies to DataFrame.append(), which has also received a sort keyword for controlling this behavior.
Build changes¶
Index division by zero fills correctly¶
Division operations on Index and subclasses will now fill division of positive numbers by zero with np.inf, division of negative numbers by zero with -np.inf and 0 / 0 with np.nan. This matches existing Series behavior. (GH19322, GH19347)
Previous behavior:
In [6]: index = pd.Int64Index([-1, 0, 1])
In [7]: index / 0
Out[7]: Int64Index([0, 0, 0], dtype='int64')
# Previous behavior yielded different results depending on the type of zero in the divisor
In [8]: index / 0.0
Out[8]: Float64Index([-inf, nan, inf], dtype='float64')
In [9]: index = pd.UInt64Index([0, 1])
In [10]: index / np.array([0, 0], dtype=np.uint64)
Out[10]: UInt64Index([0, 0], dtype='uint64')
In [11]: pd.RangeIndex(1, 5) / 0
ZeroDivisionError: integer division or modulo by zero
Current behavior:
In [12]: index = pd.Int64Index([-1, 0, 1])
# division by zero gives -infinity where negative,
# +infinity where positive, and NaN for 0 / 0
In [13]: index / 0
# The result of division by zero should not depend on
# whether the zero is int or float
In [14]: index / 0.0
In [15]: index = pd.UInt64Index([0, 1])
In [16]: index / np.array([0, 0], dtype=np.uint64)
In [17]: pd.RangeIndex(1, 5) / 0
Extraction of matching patterns from strings¶
By default, extracting matching patterns from strings with str.extract() used to return a
Series if a single group was being extracted (a DataFrame if more than one group was
extracted). As of pandas 0.23.0 str.extract() always returns a DataFrame, unless
expand is set to False. Finally, None was an accepted value for
the expand parameter (which was equivalent to False), but now raises a ValueError. (GH11386)
Previous behavior:
In [1]: s = pd.Series(['number 10', '12 eggs'])
In [2]: extracted = s.str.extract(r'.*(\d\d).*')
In [3]: extracted
Out [3]:
0 10
1 12
dtype: object
In [4]: type(extracted)
Out [4]:
pandas.core.series.Series
New behavior:
In [87]: s = pd.Series(['number 10', '12 eggs'])
In [88]: extracted = s.str.extract(r'.*(\d\d).*')
In [89]: extracted
Out[89]:
0
0 10
1 12
[2 rows x 1 columns]
In [90]: type(extracted)
Out[90]: pandas.core.frame.DataFrame
To restore previous behavior, simply set expand to False:
In [91]: s = pd.Series(['number 10', '12 eggs'])
In [92]: extracted = s.str.extract(r'.*(\d\d).*', expand=False)
In [93]: extracted
Out[93]:
0 10
1 12
Length: 2, dtype: object
In [94]: type(extracted)
Out[94]: pandas.core.series.Series
Default value for the ordered parameter of CategoricalDtype¶
The default value of the ordered parameter for CategoricalDtype has changed from False to None to allow updating of categories without impacting ordered. Behavior should remain consistent for downstream objects, such as Categorical (GH18790)
In previous versions, the default value for the ordered parameter was False. This could potentially lead to the ordered parameter unintentionally being changed from True to False when users attempt to update categories if ordered is not explicitly specified, as it would silently default to False. The new behavior for ordered=None is to retain the existing value of ordered.
New behavior:
In [2]: from pandas.api.types import CategoricalDtype
In [3]: cat = pd.Categorical(list('abcaba'), ordered=True, categories=list('cba'))
In [4]: cat
Out[4]:
[a, b, c, a, b, a]
Categories (3, object): [c < b < a]
In [5]: cdt = CategoricalDtype(categories=list('cbad'))
In [6]: cat.astype(cdt)
Out[6]:
[a, b, c, a, b, a]
Categories (4, object): [c < b < a < d]
Notice in the example above that the converted Categorical has retained ordered=True. Had the default value for ordered remained as False, the converted Categorical would have become unordered, despite ordered=False never being explicitly specified. To change the value of ordered, explicitly pass it to the new dtype, e.g. CategoricalDtype(categories=list('cbad'), ordered=False).
Note that the unintentional conversion of ordered discussed above did not arise in previous versions due to separate bugs that prevented astype from doing any type of category to category conversion (GH10696, GH18593). These bugs have been fixed in this release, and motivated changing the default value of ordered.
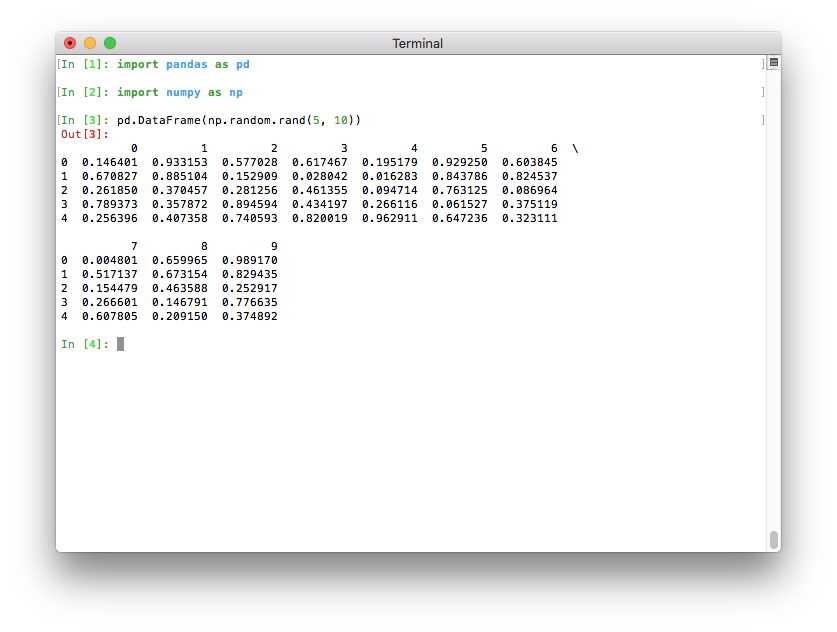
Better pretty-printing of DataFrames in a terminal¶
Previously, the default value for the maximum number of columns was
pd.options.display.max_columns=20. This meant that relatively wide data
frames would not fit within the terminal width, and pandas would introduce line
breaks to display these 20 columns. This resulted in an output that was
relatively difficult to read:
If Python runs in a terminal, the maximum number of columns is now determined
automatically so that the printed data frame fits within the current terminal
width (pd.options.display.max_columns=0) (GH17023). If Python runs
as a Jupyter kernel (such as the Jupyter QtConsole or a Jupyter notebook, as
well as in many IDEs), this value cannot be inferred automatically and is thus
set to 20 as in previous versions. In a terminal, this results in a much
nicer output:
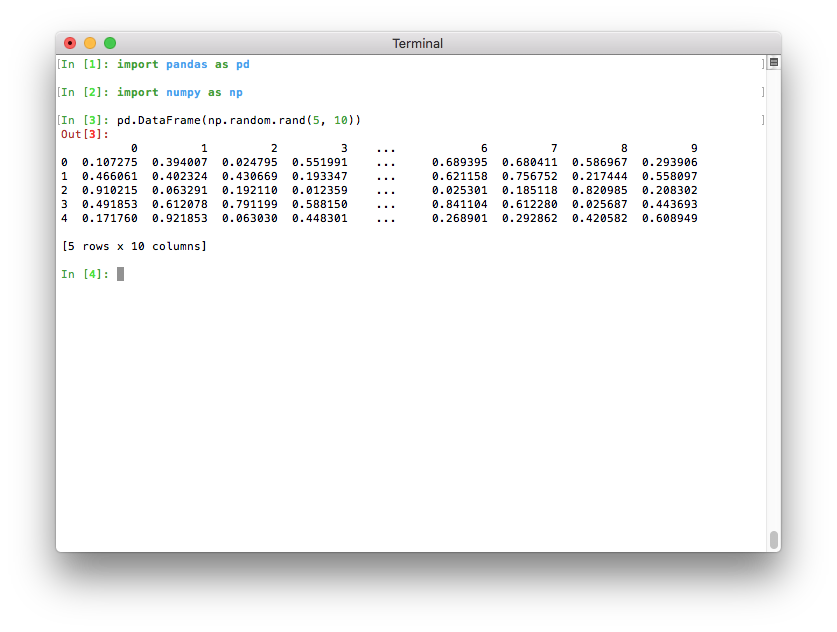
Note that if you don’t like the new default, you can always set this option yourself. To revert to the old setting, you can run this line:
pd.options.display.max_columns = 20
Datetimelike API changes¶
The default
Timedeltaconstructor now accepts anISO 8601 Durationstring as an argument (GH19040)Subtracting
NaTfrom aSerieswithdtype='datetime64[ns]'returns aSerieswithdtype='timedelta64[ns]'instead ofdtype='datetime64[ns]'(GH18808)Addition or subtraction of
NaTfromTimedeltaIndexwill returnTimedeltaIndexinstead ofDatetimeIndex(GH19124)DatetimeIndex.shift()andTimedeltaIndex.shift()will now raiseNullFrequencyError(which subclassesValueError, which was raised in older versions) when the index object frequency isNone(GH19147)Addition and subtraction of
NaNfrom aSerieswithdtype='timedelta64[ns]'will raise aTypeErrorinstead of treating theNaNasNaT(GH19274)NaTdivision withdatetime.timedeltawill now returnNaNinstead of raising (GH17876)Operations between a
Serieswith dtypedtype='datetime64[ns]'and aPeriodIndexwill correctly raisesTypeError(GH18850)Subtraction of
Serieswith timezone-awaredtype='datetime64[ns]'with mismatched timezones will raiseTypeErrorinstead ofValueError(GH18817)Timestampwill no longer silently ignore unused or invalidtzortzinfokeyword arguments (GH17690)Timestampwill no longer silently ignore invalidfreqarguments (GH5168)CacheableOffsetandWeekDayare no longer available in thepandas.tseries.offsetsmodule (GH17830)pandas.tseries.frequencies.get_freq_group()andpandas.tseries.frequencies.DAYSare removed from the public API (GH18034)Series.truncate()andDataFrame.truncate()will raise aValueErrorif the index is not sorted instead of an unhelpfulKeyError(GH17935)Series.firstandDataFrame.firstwill now raise aTypeErrorrather thanNotImplementedErrorwhen index is not aDatetimeIndex(GH20725).Series.lastandDataFrame.lastwill now raise aTypeErrorrather thanNotImplementedErrorwhen index is not aDatetimeIndex(GH20725).Restricted
DateOffsetkeyword arguments. Previously,DateOffsetsubclasses allowed arbitrary keyword arguments which could lead to unexpected behavior. Now, only valid arguments will be accepted. (GH17176, GH18226).pandas.merge()provides a more informative error message when trying to merge on timezone-aware and timezone-naive columns (GH15800)For
DatetimeIndexandTimedeltaIndexwithfreq=None, addition or subtraction of integer-dtyped array orIndexwill raiseNullFrequencyErrorinstead ofTypeError(GH19895)Timestampconstructor now accepts ananosecondkeyword or positional argument (GH18898)DatetimeIndexwill now raise anAttributeErrorwhen thetzattribute is set after instantiation (GH3746)DatetimeIndexwith apytztimezone will now return a consistentpytztimezone (GH18595)
Other API changes¶
Series.astype()andIndex.astype()with an incompatible dtype will now raise aTypeErrorrather than aValueError(GH18231)Seriesconstruction with anobjectdtyped tz-aware datetime anddtype=objectspecified, will now return anobjectdtypedSeries, previously this would infer the datetime dtype (GH18231)A
Seriesofdtype=categoryconstructed from an emptydictwill now have categories ofdtype=objectrather thandtype=float64, consistently with the case in which an empty list is passed (GH18515)All-NaN levels in a
MultiIndexare now assignedfloatrather thanobjectdtype, promoting consistency withIndex(GH17929).Levels names of a
MultiIndex(when not None) are now required to be unique: trying to create aMultiIndexwith repeated names will raise aValueError(GH18872)Both construction and renaming of
Index/MultiIndexwith non-hashablename/nameswill now raiseTypeError(GH20527)Index.map()can now acceptSeriesand dictionary input objects (GH12756, GH18482, GH18509).DataFrame.unstack()will now default to filling withnp.nanforobjectcolumns. (GH12815)IntervalIndexconstructor will raise if theclosedparameter conflicts with how the input data is inferred to be closed (GH18421)Inserting missing values into indexes will work for all types of indexes and automatically insert the correct type of missing value (
NaN,NaT, etc.) regardless of the type passed in (GH18295)When created with duplicate labels,
MultiIndexnow raises aValueError. (GH17464)Series.fillna()now raises aTypeErrorinstead of aValueErrorwhen passed a list, tuple or DataFrame as avalue(GH18293)pandas.DataFrame.merge()no longer casts afloatcolumn toobjectwhen merging onintandfloatcolumns (GH16572)pandas.merge()now raises aValueErrorwhen trying to merge on incompatible data types (GH9780)The default NA value for
UInt64Indexhas changed from 0 toNaN, which impacts methods that mask with NA, such asUInt64Index.where()(GH18398)Refactored
setup.pyto usefind_packagesinstead of explicitly listing out all subpackages (GH18535)Rearranged the order of keyword arguments in
read_excel()to align withread_csv()(GH16672)wide_to_long()previously kept numeric-like suffixes asobjectdtype. Now they are cast to numeric if possible (GH17627)In
read_excel(), thecommentargument is now exposed as a named parameter (GH18735)Rearranged the order of keyword arguments in
read_excel()to align withread_csv()(GH16672)The options
html.borderandmode.use_inf_as_nullwere deprecated in prior versions, these will now showFutureWarningrather than aDeprecationWarning(GH19003)IntervalIndexandIntervalDtypeno longer support categorical, object, and string subtypes (GH19016)IntervalDtypenow returnsTruewhen compared against'interval'regardless of subtype, andIntervalDtype.namenow returns'interval'regardless of subtype (GH18980)KeyErrornow raises instead ofValueErrorindrop(),drop(),drop(),drop()when dropping a non-existent element in an axis with duplicates (GH19186)Series.to_csv()now accepts acompressionargument that works in the same way as thecompressionargument inDataFrame.to_csv()(GH18958)Set operations (union, difference…) on
IntervalIndexwith incompatible index types will now raise aTypeErrorrather than aValueError(GH19329)DateOffsetobjects render more simply, e.g.<DateOffset: days=1>instead of<DateOffset: kwds={'days': 1}>(GH19403)Categorical.fillnanow validates itsvalueandmethodkeyword arguments. It now raises when both or none are specified, matching the behavior ofSeries.fillna()(GH19682)pd.to_datetime('today')now returns a datetime, consistent withpd.Timestamp('today'); previouslypd.to_datetime('today')returned a.normalized()datetime (GH19935)Series.str.replace()now takes an optionalregexkeyword which, when set toFalse, uses literal string replacement rather than regex replacement (GH16808)DatetimeIndex.strftime()andPeriodIndex.strftime()now return anIndexinstead of a numpy array to be consistent with similar accessors (GH20127)Constructing a Series from a list of length 1 no longer broadcasts this list when a longer index is specified (GH19714, GH20391).
DataFrame.to_dict()withorient='index'no longer casts int columns to float for a DataFrame with only int and float columns (GH18580)A user-defined-function that is passed to
Series.rolling().aggregate(),DataFrame.rolling().aggregate(), or its expanding cousins, will now always be passed aSeries, rather than anp.array;.apply()only has therawkeyword, see here. This is consistent with the signatures of.aggregate()across pandas (GH20584)Rolling and Expanding types raise
NotImplementedErrorupon iteration (GH11704).
Deprecations¶
Series.from_arrayandSparseSeries.from_arrayare deprecated. Use the normal constructorSeries(..)andSparseSeries(..)instead (GH18213).DataFrame.as_matrixis deprecated. UseDataFrame.valuesinstead (GH18458).Series.asobject,DatetimeIndex.asobject,PeriodIndex.asobjectandTimeDeltaIndex.asobjecthave been deprecated. Use.astype(object)instead (GH18572)Grouping by a tuple of keys now emits a
FutureWarningand is deprecated. In the future, a tuple passed to'by'will always refer to a single key that is the actual tuple, instead of treating the tuple as multiple keys. To retain the previous behavior, use a list instead of a tuple (GH18314)Series.validis deprecated. UseSeries.dropna()instead (GH18800).read_excel()has deprecated theskip_footerparameter. Useskipfooterinstead (GH18836)ExcelFile.parse()has deprecatedsheetnamein favor ofsheet_namefor consistency withread_excel()(GH20920).The
is_copyattribute is deprecated and will be removed in a future version (GH18801).IntervalIndex.from_intervalsis deprecated in favor of theIntervalIndexconstructor (GH19263)DataFrame.from_itemsis deprecated. UseDataFrame.from_dict()instead, orDataFrame.from_dict(OrderedDict())if you wish to preserve the key order (GH17320, GH17312)Indexing a
MultiIndexor aFloatIndexwith a list containing some missing keys will now show aFutureWarning, which is consistent with other types of indexes (GH17758).The
broadcastparameter of.apply()is deprecated in favor ofresult_type='broadcast'(GH18577)The
reduceparameter of.apply()is deprecated in favor ofresult_type='reduce'(GH18577)The
orderparameter offactorize()is deprecated and will be removed in a future release (GH19727)Timestamp.weekday_name,DatetimeIndex.weekday_name, andSeries.dt.weekday_nameare deprecated in favor ofTimestamp.day_name(),DatetimeIndex.day_name(), andSeries.dt.day_name()(GH12806)pandas.tseries.plotting.tsplotis deprecated. UseSeries.plot()instead (GH18627)Index.summary()is deprecated and will be removed in a future version (GH18217)NDFrame.get_ftype_counts()is deprecated and will be removed in a future version (GH18243)The
convert_datetime64parameter inDataFrame.to_records()has been deprecated and will be removed in a future version. The NumPy bug motivating this parameter has been resolved. The default value for this parameter has also changed fromTruetoNone(GH18160).Series.rolling().apply(),DataFrame.rolling().apply(),Series.expanding().apply(), andDataFrame.expanding().apply()have deprecated passing annp.arrayby default. One will need to pass the newrawparameter to be explicit about what is passed (GH20584)The
data,base,strides,flagsanditemsizeproperties of theSeriesandIndexclasses have been deprecated and will be removed in a future version (GH20419).DatetimeIndex.offsetis deprecated. UseDatetimeIndex.freqinstead (GH20716)Floor division between an integer ndarray and a
Timedeltais deprecated. Divide byTimedelta.valueinstead (GH19761)Setting
PeriodIndex.freq(which was not guaranteed to work correctly) is deprecated. UsePeriodIndex.asfreq()instead (GH20678)Index.get_duplicates()is deprecated and will be removed in a future version (GH20239)The previous default behavior of negative indices in
Categorical.takeis deprecated. In a future version it will change from meaning missing values to meaning positional indices from the right. The future behavior is consistent withSeries.take()(GH20664).Passing multiple axes to the
axisparameter inDataFrame.dropna()has been deprecated and will be removed in a future version (GH20987)
Removal of prior version deprecations/changes¶
Warnings against the obsolete usage
Categorical(codes, categories), which were emitted for instance when the first two arguments toCategorical()had different dtypes, and recommended the use ofCategorical.from_codes, have now been removed (GH8074)The
levelsandlabelsattributes of aMultiIndexcan no longer be set directly (GH4039).pd.tseries.util.pivot_annualhas been removed (deprecated since v0.19). Usepivot_tableinstead (GH18370)pd.tseries.util.isleapyearhas been removed (deprecated since v0.19). Use.is_leap_yearproperty in Datetime-likes instead (GH18370)pd.ordered_mergehas been removed (deprecated since v0.19). Usepd.merge_orderedinstead (GH18459)The
SparseListclass has been removed (GH14007)The
pandas.io.wbandpandas.io.datastub modules have been removed (GH13735)Categorical.from_arrayhas been removed (GH13854)The
freqandhowparameters have been removed from therolling/expanding/ewmmethods of DataFrame and Series (deprecated since v0.18). Instead, resample before calling the methods. (GH18601 & GH18668)DatetimeIndex.to_datetime,Timestamp.to_datetime,PeriodIndex.to_datetime, andIndex.to_datetimehave been removed (GH8254, GH14096, GH14113)read_csv()has dropped theskip_footerparameter (GH13386)read_csv()has dropped theas_recarrayparameter (GH13373)read_csv()has dropped thebuffer_linesparameter (GH13360)read_csv()has dropped thecompact_intsanduse_unsignedparameters (GH13323)The
Timestampclass has dropped theoffsetattribute in favor offreq(GH13593)The
Series,Categorical, andIndexclasses have dropped thereshapemethod (GH13012)pandas.tseries.frequencies.get_standard_freqhas been removed in favor ofpandas.tseries.frequencies.to_offset(freq).rule_code(GH13874)The
freqstrkeyword has been removed frompandas.tseries.frequencies.to_offsetin favor offreq(GH13874)The
Panel4DandPanelNDclasses have been removed (GH13776)The
Panelclass has dropped theto_longandtoLongmethods (GH19077)The options
display.line_withanddisplay.heightare removed in favor ofdisplay.widthanddisplay.max_rowsrespectively (GH4391, GH19107)The
labelsattribute of theCategoricalclass has been removed in favor ofCategorical.codes(GH7768)The
flavorparameter have been removed from func:to_sql method (GH13611)The modules
pandas.tools.hashingandpandas.util.hashinghave been removed (GH16223)The top-level functions
pd.rolling_*,pd.expanding_*andpd.ewm*have been removed (Deprecated since v0.18). Instead, use the DataFrame/Series methodsrolling,expandingandewm(GH18723)Imports from
pandas.core.commonfor functions such asis_datetime64_dtypeare now removed. These are located inpandas.api.types. (GH13634, GH19769)The
infer_dstkeyword inSeries.tz_localize(),DatetimeIndex.tz_localize()andDatetimeIndexhave been removed.infer_dst=Trueis equivalent toambiguous='infer', andinfer_dst=Falsetoambiguous='raise'(GH7963).When
.resample()was changed from an eager to a lazy operation, like.groupby()in v0.18.0, we put in place compatibility (with aFutureWarning), so operations would continue to work. This is now fully removed, so aResamplerwill no longer forward compat operations (GH20554)Remove long deprecated
axis=Noneparameter from.replace()(GH20271)
Performance improvements¶
Indexers on
SeriesorDataFrameno longer create a reference cycle (GH17956)Added a keyword argument,
cache, toto_datetime()that improved the performance of converting duplicate datetime arguments (GH11665)DateOffsetarithmetic performance is improved (GH18218)Converting a
SeriesofTimedeltaobjects to days, seconds, etc… sped up through vectorization of underlying methods (GH18092)Improved performance of
.map()with aSeries/dictinput (GH15081)The overridden
Timedeltaproperties of days, seconds and microseconds have been removed, leveraging their built-in Python versions instead (GH18242)Seriesconstruction will reduce the number of copies made of the input data in certain cases (GH17449)Improved performance of
Series.dt.date()andDatetimeIndex.date()(GH18058)Improved performance of
Series.dt.time()andDatetimeIndex.time()(GH18461)Improved performance of
IntervalIndex.symmetric_difference()(GH18475)Improved performance of
DatetimeIndexandSeriesarithmetic operations with Business-Month and Business-Quarter frequencies (GH18489)Series()/DataFrame()tab completion limits to 100 values, for better performance. (GH18587)Improved performance of
DataFrame.median()withaxis=1when bottleneck is not installed (GH16468)Improved performance of
MultiIndex.get_loc()for large indexes, at the cost of a reduction in performance for small ones (GH18519)Improved performance of
MultiIndex.remove_unused_levels()when there are no unused levels, at the cost of a reduction in performance when there are (GH19289)Improved performance of
Index.get_loc()for non-unique indexes (GH19478)Improved performance of pairwise
.rolling()and.expanding()with.cov()and.corr()operations (GH17917)Improved performance of
pandas.core.groupby.GroupBy.rank()(GH15779)Improved performance of variable
.rolling()on.min()and.max()(GH19521)Improved performance of
pandas.core.groupby.GroupBy.ffill()andpandas.core.groupby.GroupBy.bfill()(GH11296)Improved performance of
pandas.core.groupby.GroupBy.any()andpandas.core.groupby.GroupBy.all()(GH15435)Improved performance of
pandas.core.groupby.GroupBy.pct_change()(GH19165)Improved performance of
Series.isin()in the case of categorical dtypes (GH20003)Improved performance of
getattr(Series, attr)when the Series has certain index types. This manifested in slow printing of large Series with aDatetimeIndex(GH19764)Fixed a performance regression for
GroupBy.nth()andGroupBy.last()with some object columns (GH19283)Improved performance of
pandas.core.arrays.Categorical.from_codes()(GH18501)
Documentation changes¶
Thanks to all of the contributors who participated in the pandas Documentation Sprint, which took place on March 10th. We had about 500 participants from over 30 locations across the world. You should notice that many of the API docstrings have greatly improved.
There were too many simultaneous contributions to include a release note for each improvement, but this GitHub search should give you an idea of how many docstrings were improved.
Special thanks to Marc Garcia for organizing the sprint. For more information, read the NumFOCUS blogpost recapping the sprint.
Changed spelling of “numpy” to “NumPy”, and “python” to “Python”. (GH19017)
Consistency when introducing code samples, using either colon or period. Rewrote some sentences for greater clarity, added more dynamic references to functions, methods and classes. (GH18941, GH18948, GH18973, GH19017)
Added a reference to
DataFrame.assign()in the concatenate section of the merging documentation (GH18665)
Bug fixes¶
Categorical¶
Warning
A class of bugs were introduced in pandas 0.21 with CategoricalDtype that
affects the correctness of operations like merge, concat, and
indexing when comparing multiple unordered Categorical arrays that have
the same categories, but in a different order. We highly recommend upgrading
or manually aligning your categories before doing these operations.
Bug in
Categorical.equalsreturning the wrong result when comparing two unorderedCategoricalarrays with the same categories, but in a different order (GH16603)Bug in
pandas.api.types.union_categoricals()returning the wrong result when for unordered categoricals with the categories in a different order. This affectedpandas.concat()with Categorical data (GH19096).Bug in
pandas.merge()returning the wrong result when joining on an unorderedCategoricalthat had the same categories but in a different order (GH19551)Bug in
CategoricalIndex.get_indexer()returning the wrong result whentargetwas an unorderedCategoricalthat had the same categories asselfbut in a different order (GH19551)Bug in
Index.astype()with a categorical dtype where the resultant index is not converted to aCategoricalIndexfor all types of index (GH18630)Bug in
Series.astype()andCategorical.astype()where an existing categorical data does not get updated (GH10696, GH18593)Bug in
Series.str.split()withexpand=Trueincorrectly raising an IndexError on empty strings (GH20002).Bug in
Indexconstructor withdtype=CategoricalDtype(...)wherecategoriesandorderedare not maintained (GH19032)Bug in
Seriesconstructor with scalar anddtype=CategoricalDtype(...)wherecategoriesandorderedare not maintained (GH19565)Bug in
Categorical.__iter__not converting to Python types (GH19909)Bug in
pandas.factorize()returning the unique codes for theuniques. This now returns aCategoricalwith the same dtype as the input (GH19721)Bug in
pandas.factorize()including an item for missing values in theuniquesreturn value (GH19721)Bug in
Series.take()with categorical data interpreting-1inindicesas missing value markers, rather than the last element of the Series (GH20664)
Datetimelike¶
Bug in
Series.__sub__()subtracting a non-nanosecondnp.datetime64object from aSeriesgave incorrect results (GH7996)Bug in
DatetimeIndex,TimedeltaIndexaddition and subtraction of zero-dimensional integer arrays gave incorrect results (GH19012)Bug in
DatetimeIndexandTimedeltaIndexwhere adding or subtracting an array-like ofDateOffsetobjects either raised (np.array,pd.Index) or broadcast incorrectly (pd.Series) (GH18849)Bug in
Series.__add__()adding Series with dtypetimedelta64[ns]to a timezone-awareDatetimeIndexincorrectly dropped timezone information (GH13905)Adding a
Periodobject to adatetimeorTimestampobject will now correctly raise aTypeError(GH17983)Bug in
Timestampwhere comparison with an array ofTimestampobjects would result in aRecursionError(GH15183)Bug in
Seriesfloor-division where operating on a scalartimedeltaraises an exception (GH18846)Bug in
DatetimeIndexwhere the repr was not showing high-precision time values at the end of a day (e.g., 23:59:59.999999999) (GH19030)Bug in
.astype()to non-ns timedelta units would hold the incorrect dtype (GH19176, GH19223, GH12425)Bug in subtracting
SeriesfromNaTincorrectly returningNaT(GH19158)Bug in
Series.truncate()which raisesTypeErrorwith a monotonicPeriodIndex(GH17717)Bug in
pct_change()usingperiodsandfreqreturned different length outputs (GH7292)Bug in comparison of
DatetimeIndexagainstNoneordatetime.dateobjects raisingTypeErrorfor==and!=comparisons instead of all-Falseand all-True, respectively (GH19301)Bug in
Timestampandto_datetime()where a string representing a barely out-of-bounds timestamp would be incorrectly rounded down instead of raisingOutOfBoundsDatetime(GH19382)Bug in
Timestamp.floor()DatetimeIndex.floor()where time stamps far in the future and past were not rounded correctly (GH19206)Bug in
to_datetime()where passing an out-of-bounds datetime witherrors='coerce'andutc=Truewould raiseOutOfBoundsDatetimeinstead of parsing toNaT(GH19612)Bug in
DatetimeIndexandTimedeltaIndexaddition and subtraction where name of the returned object was not always set consistently. (GH19744)Bug in
DatetimeIndexandTimedeltaIndexaddition and subtraction where operations with numpy arrays raisedTypeError(GH19847)Bug in
DatetimeIndexandTimedeltaIndexwhere setting thefreqattribute was not fully supported (GH20678)
Timedelta¶
Bug in
Timedelta.__mul__()where multiplying byNaTreturnedNaTinstead of raising aTypeError(GH19819)Bug in
Serieswithdtype='timedelta64[ns]'where addition or subtraction ofTimedeltaIndexhad results cast todtype='int64'(GH17250)Bug in
Serieswithdtype='timedelta64[ns]'where addition or subtraction ofTimedeltaIndexcould return aSerieswith an incorrect name (GH19043)Bug in
Timedelta.__floordiv__()andTimedelta.__rfloordiv__()dividing by many incompatible numpy objects was incorrectly allowed (GH18846)Bug where dividing a scalar timedelta-like object with
TimedeltaIndexperformed the reciprocal operation (GH19125)Bug in
TimedeltaIndexwhere division by aSerieswould return aTimedeltaIndexinstead of aSeries(GH19042)Bug in
Timedelta.__add__(),Timedelta.__sub__()where adding or subtracting anp.timedelta64object would return anothernp.timedelta64instead of aTimedelta(GH19738)Bug in
Timedelta.__floordiv__(),Timedelta.__rfloordiv__()where operating with aTickobject would raise aTypeErrorinstead of returning a numeric value (GH19738)Bug in
Period.asfreq()where periods neardatetime(1, 1, 1)could be converted incorrectly (GH19643, GH19834)Bug in
Timedelta.total_seconds()causing precision errors, for exampleTimedelta('30S').total_seconds()==30.000000000000004(GH19458)Bug in
Timedelta.__rmod__()where operating with anumpy.timedelta64returned atimedelta64object instead of aTimedelta(GH19820)Multiplication of
TimedeltaIndexbyTimedeltaIndexwill now raiseTypeErrorinstead of raisingValueErrorin cases of length mismatch (GH19333)Bug in indexing a
TimedeltaIndexwith anp.timedelta64object which was raising aTypeError(GH20393)
Timezones¶
Bug in creating a
Seriesfrom an array that contains both tz-naive and tz-aware values will result in aSerieswhose dtype is tz-aware instead of object (GH16406)Bug in comparison of timezone-aware
DatetimeIndexagainstNaTincorrectly raisingTypeError(GH19276)Bug in
DatetimeIndex.astype()when converting between timezone aware dtypes, and converting from timezone aware to naive (GH18951)Bug in comparing
DatetimeIndex, which failed to raiseTypeErrorwhen attempting to compare timezone-aware and timezone-naive datetimelike objects (GH18162)Bug in localization of a naive, datetime string in a
Seriesconstructor with adatetime64[ns, tz]dtype (GH174151)Timestamp.replace()will now handle Daylight Savings transitions gracefully (GH18319)Bug in tz-aware
DatetimeIndexwhere addition/subtraction with aTimedeltaIndexor array withdtype='timedelta64[ns]'was incorrect (GH17558)Bug in
DatetimeIndex.insert()where insertingNaTinto a timezone-aware index incorrectly raised (GH16357)Bug in
DataFrameconstructor, where tz-aware Datetimeindex and a given column name will result in an emptyDataFrame(GH19157)Bug in
Timestamp.tz_localize()where localizing a timestamp near the minimum or maximum valid values could overflow and return a timestamp with an incorrect nanosecond value (GH12677)Bug when iterating over
DatetimeIndexthat was localized with fixed timezone offset that rounded nanosecond precision to microseconds (GH19603)Bug in
DataFrame.diff()that raised anIndexErrorwith tz-aware values (GH18578)Bug in
melt()that converted tz-aware dtypes to tz-naive (GH15785)Bug in
Dataframe.count()that raised anValueError, ifDataframe.dropna()was called for a single column with timezone-aware values. (GH13407)
Offsets¶
Bug in
WeekOfMonthandWeekwhere addition and subtraction did not roll correctly (GH18510, GH18672, GH18864)Bug in
WeekOfMonthandLastWeekOfMonthwhere default keyword arguments for constructor raisedValueError(GH19142)Bug in
FY5253Quarter,LastWeekOfMonthwhere rollback and rollforward behavior was inconsistent with addition and subtraction behavior (GH18854)Bug in
FY5253wheredatetimeaddition and subtraction incremented incorrectly for dates on the year-end but not normalized to midnight (GH18854)Bug in
FY5253where date offsets could incorrectly raise anAssertionErrorin arithmetic operations (GH14774)
Numeric¶
Bug in
Seriesconstructor with an int or float list where specifyingdtype=str,dtype='str'ordtype='U'failed to convert the data elements to strings (GH16605)Bug in
Indexmultiplication and division methods where operating with aSerieswould return anIndexobject instead of aSeriesobject (GH19042)Bug in the
DataFrameconstructor in which data containing very large positive or very large negative numbers was causingOverflowError(GH18584)Bug in
Indexconstructor withdtype='uint64'where int-like floats were not coerced toUInt64Index(GH18400)Bug in
DataFrameflex arithmetic (e.g.df.add(other, fill_value=foo)) with afill_valueother thanNonefailed to raiseNotImplementedErrorin corner cases where either the frame orotherhas length zero (GH19522)Multiplication and division of numeric-dtyped
Indexobjects with timedelta-like scalars returnsTimedeltaIndexinstead of raisingTypeError(GH19333)Bug where
NaNwas returned instead of 0 bySeries.pct_change()andDataFrame.pct_change()whenfill_methodis notNone(GH19873)
Strings¶
Bug in
Series.str.get()with a dictionary in the values and the index not in the keys, raisingKeyError(GH20671)
Indexing¶
Bug in
Indexconstruction from list of mixed type tuples (GH18505)Bug in
Index.drop()when passing a list of both tuples and non-tuples (GH18304)Bug in
DataFrame.drop(),Panel.drop(),Series.drop(),Index.drop()where noKeyErroris raised when dropping a non-existent element from an axis that contains duplicates (GH19186)Bug in indexing a datetimelike
Indexthat raisedValueErrorinstead ofIndexError(GH18386).Index.to_series()now acceptsindexandnamekwargs (GH18699)DatetimeIndex.to_series()now acceptsindexandnamekwargs (GH18699)Bug in indexing non-scalar value from
Serieshaving non-uniqueIndexwill return value flattened (GH17610)Bug in indexing with iterator containing only missing keys, which raised no error (GH20748)
Fixed inconsistency in
.ixbetween list and scalar keys when the index has integer dtype and does not include the desired keys (GH20753)Bug in
__setitem__when indexing aDataFramewith a 2-d boolean ndarray (GH18582)Bug in
str.extractallwhen there were no matches emptyIndexwas returned instead of appropriateMultiIndex(GH19034)Bug in
IntervalIndexwhere empty and purely NA data was constructed inconsistently depending on the construction method (GH18421)Bug in
IntervalIndex.symmetric_difference()where the symmetric difference with a non-IntervalIndexdid not raise (GH18475)Bug in
IntervalIndexwhere set operations that returned an emptyIntervalIndexhad the wrong dtype (GH19101)Bug in
DataFrame.drop_duplicates()where noKeyErroris raised when passing in columns that don’t exist on theDataFrame(GH19726)Bug in
Indexsubclasses constructors that ignore unexpected keyword arguments (GH19348)Bug in
Index.difference()when taking difference of anIndexwith itself (GH20040)Bug in
DataFrame.first_valid_index()andDataFrame.last_valid_index()in presence of entire rows of NaNs in the middle of values (GH20499).Bug in
IntervalIndexwhere some indexing operations were not supported for overlapping or non-monotonicuint64data (GH20636)Bug in
Series.is_uniquewhere extraneous output in stderr is shown if Series contains objects with__ne__defined (GH20661)Bug in
.locassignment with a single-element list-like incorrectly assigns as a list (GH19474)Bug in partial string indexing on a
Series/DataFramewith a monotonic decreasingDatetimeIndex(GH19362)Bug in performing in-place operations on a
DataFramewith a duplicateIndex(GH17105)Bug in
IntervalIndex.get_loc()andIntervalIndex.get_indexer()when used with anIntervalIndexcontaining a single interval (GH17284, GH20921)Bug in
.locwith auint64indexer (GH20722)
MultiIndex¶
Bug in
MultiIndex.__contains__()where non-tuple keys would returnTrueeven if they had been dropped (GH19027)Bug in
MultiIndex.set_labels()which would cause casting (and potentially clipping) of the new labels if thelevelargument is not 0 or a list like [0, 1, … ] (GH19057)Bug in
MultiIndex.get_level_values()which would return an invalid index on level of ints with missing values (GH17924)Bug in
MultiIndex.unique()when called on emptyMultiIndex(GH20568)Bug in
MultiIndex.unique()which would not preserve level names (GH20570)Bug in
MultiIndex.remove_unused_levels()which would fill nan values (GH18417)Bug in
MultiIndex.from_tuples()which would fail to take zipped tuples in python3 (GH18434)Bug in
MultiIndex.get_loc()which would fail to automatically cast values between float and int (GH18818, GH15994)Bug in
MultiIndex.get_loc()which would cast boolean to integer labels (GH19086)Bug in
MultiIndex.get_loc()which would fail to locate keys containingNaN(GH18485)Bug in
MultiIndex.get_loc()in largeMultiIndex, would fail when levels had different dtypes (GH18520)Bug in indexing where nested indexers having only numpy arrays are handled incorrectly (GH19686)
IO¶
read_html()now rewinds seekable IO objects after parse failure, before attempting to parse with a new parser. If a parser errors and the object is non-seekable, an informative error is raised suggesting the use of a different parser (GH17975)DataFrame.to_html()now has an option to add an id to the leading<table>tag (GH8496)Bug in
read_msgpack()with a non existent file is passed in Python 2 (GH15296)Bug in
read_csv()where aMultiIndexwith duplicate columns was not being mangled appropriately (GH18062)Bug in
read_csv()where missing values were not being handled properly whenkeep_default_na=Falsewith dictionaryna_values(GH19227)Bug in
read_csv()causing heap corruption on 32-bit, big-endian architectures (GH20785)Bug in
read_sas()where a file with 0 variables gave anAttributeErrorincorrectly. Now it gives anEmptyDataError(GH18184)Bug in
DataFrame.to_latex()where pairs of braces meant to serve as invisible placeholders were escaped (GH18667)Bug in
DataFrame.to_latex()where aNaNin aMultiIndexwould cause anIndexErroror incorrect output (GH14249)Bug in
DataFrame.to_latex()where a non-string index-level name would result in anAttributeError(GH19981)Bug in
DataFrame.to_latex()where the combination of an index name and theindex_names=Falseoption would result in incorrect output (GH18326)Bug in
DataFrame.to_latex()where aMultiIndexwith an empty string as its name would result in incorrect output (GH18669)Bug in
DataFrame.to_latex()where missing space characters caused wrong escaping and produced non-valid latex in some cases (GH20859)Bug in
read_json()where large numeric values were causing anOverflowError(GH18842)Bug in
DataFrame.to_parquet()where an exception was raised if the write destination is S3 (GH19134)Intervalnow supported inDataFrame.to_excel()for all Excel file types (GH19242)Timedeltanow supported inDataFrame.to_excel()for all Excel file types (GH19242, GH9155, GH19900)Bug in
pandas.io.stata.StataReader.value_labels()raising anAttributeErrorwhen called on very old files. Now returns an empty dict (GH19417)Bug in
read_pickle()when unpickling objects withTimedeltaIndexorFloat64Indexcreated with pandas prior to version 0.20 (GH19939)Bug in
pandas.io.json.json_normalize()where sub-records are not properly normalized if any sub-records values are NoneType (GH20030)Bug in
usecolsparameter inread_csv()where error is not raised correctly when passing a string. (GH20529)Bug in
HDFStore.keys()when reading a file with a soft link causes exception (GH20523)Bug in
HDFStore.select_column()where a key which is not a valid store raised anAttributeErrorinstead of aKeyError(GH17912)
Plotting¶
Better error message when attempting to plot but matplotlib is not installed (GH19810).
DataFrame.plot()now raises aValueErrorwhen thexoryargument is improperly formed (GH18671)Bug in
DataFrame.plot()whenxandyarguments given as positions caused incorrect referenced columns for line, bar and area plots (GH20056)Bug in formatting tick labels with
datetime.time()and fractional seconds (GH18478).Series.plot.kde()has exposed the argsindandbw_methodin the docstring (GH18461). The argumentindmay now also be an integer (number of sample points).DataFrame.plot()now supports multiple columns to theyargument (GH19699)
GroupBy/resample/rolling¶
Bug when grouping by a single column and aggregating with a class like
listortuple(GH18079)Fixed regression in
DataFrame.groupby()which would not emit an error when called with a tuple key not in the index (GH18798)Bug in
DataFrame.resample()which silently ignored unsupported (or mistyped) options forlabel,closedandconvention(GH19303)Bug in
DataFrame.groupby()where tuples were interpreted as lists of keys rather than as keys (GH17979, GH18249)Bug in
DataFrame.groupby()where aggregation byfirst/last/min/maxwas causing timestamps to lose precision (GH19526)Bug in
DataFrame.transform()where particular aggregation functions were being incorrectly cast to match the dtype(s) of the grouped data (GH19200)Bug in
DataFrame.groupby()passing theon=kwarg, and subsequently using.apply()(GH17813)Bug in
DataFrame.resample().aggregatenot raising aKeyErrorwhen aggregating a non-existent column (GH16766, GH19566)Bug in
DataFrameGroupBy.cumsum()andDataFrameGroupBy.cumprod()whenskipnawas passed (GH19806)Bug in
DataFrame.resample()that dropped timezone information (GH13238)Bug in
DataFrame.groupby()where transformations usingnp.allandnp.anywere raising aValueError(GH20653)Bug in
DataFrame.resample()whereffill,bfill,pad,backfill,fillna,interpolate, andasfreqwere ignoringloffset. (GH20744)Bug in
DataFrame.groupby()when applying a function that has mixed data types and the user supplied function can fail on the grouping column (GH20949)Bug in
DataFrameGroupBy.rolling().apply()where operations performed against the associatedDataFrameGroupByobject could impact the inclusion of the grouped item(s) in the result (GH14013)
Sparse¶
Bug in which creating a
SparseDataFramefrom a denseSeriesor an unsupported type raised an uncontrolled exception (GH19374)Bug in
SparseDataFrame.to_csvcausing exception (GH19384)Bug in
SparseSeries.memory_usagewhich caused segfault by accessing non sparse elements (GH19368)Bug in constructing a
SparseArray: ifdatais a scalar andindexis defined it will coerce tofloat64regardless of scalar’s dtype. (GH19163)
Reshaping¶
Bug in
DataFrame.merge()where referencing aCategoricalIndexby name, where thebykwarg wouldKeyError(GH20777)Bug in
DataFrame.stack()which fails trying to sort mixed type levels under Python 3 (GH18310)Bug in
DataFrame.unstack()which casts int to float ifcolumnsis aMultiIndexwith unused levels (GH17845)Bug in
DataFrame.unstack()which raises an error ifindexis aMultiIndexwith unused labels on the unstacked level (GH18562)Fixed construction of a
Seriesfrom adictcontainingNaNas key (GH18480)Fixed construction of a
DataFramefrom adictcontainingNaNas key (GH18455)Disabled construction of a
Serieswhere len(index) > len(data) = 1, which previously would broadcast the data item, and now raises aValueError(GH18819)Suppressed error in the construction of a
DataFramefrom adictcontaining scalar values when the corresponding keys are not included in the passed index (GH18600)Fixed (changed from
objecttofloat64) dtype ofDataFrameinitialized with axes, no data, anddtype=int(GH19646)Bug in
Series.rank()whereSeriescontainingNaTmodifies theSeriesinplace (GH18521)Bug in
cut()which fails when using readonly arrays (GH18773)Bug in
DataFrame.pivot_table()which fails when theaggfuncarg is of type string. The behavior is now consistent with other methods likeaggandapply(GH18713)Bug in
DataFrame.merge()in which merging usingIndexobjects as vectors raised an Exception (GH19038)Bug in
DataFrame.stack(),DataFrame.unstack(),Series.unstack()which were not returning subclasses (GH15563)Bug in timezone comparisons, manifesting as a conversion of the index to UTC in
.concat()(GH18523)Bug in
concat()when concatenating sparse and dense series it returns only aSparseDataFrame. Should be aDataFrame. (GH18914, GH18686, and GH16874)Improved error message for
DataFrame.merge()when there is no common merge key (GH19427)Bug in
DataFrame.join()which does anouterinstead of aleftjoin when being called with multiple DataFrames and some have non-unique indices (GH19624)Series.rename()now acceptsaxisas a kwarg (GH18589)Bug in
rename()where an Index of same-length tuples was converted to a MultiIndex (GH19497)Comparisons between
SeriesandIndexwould return aSerieswith an incorrect name, ignoring theIndex’s name attribute (GH19582)Bug in
qcut()where datetime and timedelta data withNaTpresent raised aValueError(GH19768)Bug in
DataFrame.iterrows(), which would infers strings not compliant to ISO8601 to datetimes (GH19671)Bug in
Seriesconstructor withCategoricalwhere aValueErroris not raised when an index of different length is given (GH19342)Bug in
DataFrame.astype()where column metadata is lost when converting to categorical or a dictionary of dtypes (GH19920)Bug in
cut()andqcut()where timezone information was dropped (GH19872)Bug in
Seriesconstructor with adtype=str, previously raised in some cases (GH19853)Bug in
get_dummies(), andselect_dtypes(), where duplicate column names caused incorrect behavior (GH20848)Bug in
isna(), which cannot handle ambiguous typed lists (GH20675)Bug in
concat()which raises an error when concatenating TZ-aware dataframes and all-NaT dataframes (GH12396)Bug in
concat()which raises an error when concatenating empty TZ-aware series (GH18447)
Other¶
Improved error message when attempting to use a Python keyword as an identifier in a
numexprbacked query (GH18221)Bug in accessing a
pandas.get_option(), which raisedKeyErrorrather thanOptionErrorwhen looking up a non-existent option key in some cases (GH19789)Bug in
testing.assert_series_equal()andtesting.assert_frame_equal()for Series or DataFrames with differing unicode data (GH20503)
Contributors¶
A total of 328 people contributed patches to this release. People with a “+” by their names contributed a patch for the first time.
Aaron Critchley
AbdealiJK +
Adam Hooper +
Albert Villanova del Moral
Alejandro Giacometti +
Alejandro Hohmann +
Alex Rychyk
Alexander Buchkovsky
Alexander Lenail +
Alexander Michael Schade
Aly Sivji +
Andreas Költringer +
Andrew
Andrew Bui +
András Novoszáth +
Andy Craze +
Andy R. Terrel
Anh Le +
Anil Kumar Pallekonda +
Antoine Pitrou +
Antonio Linde +
Antonio Molina +
Antonio Quinonez +
Armin Varshokar +
Artem Bogachev +
Avi Sen +
Azeez Oluwafemi +
Ben Auffarth +
Bernhard Thiel +
Bhavesh Poddar +
BielStela +
Blair +
Bob Haffner
Brett Naul +
Brock Mendel
Bryce Guinta +
Carlos Eduardo Moreira dos Santos +
Carlos García Márquez +
Carol Willing
Cheuk Ting Ho +
Chitrank Dixit +
Chris
Chris Burr +
Chris Catalfo +
Chris Mazzullo
Christian Chwala +
Cihan Ceyhan +
Clemens Brunner
Colin +
Cornelius Riemenschneider
Crystal Gong +
DaanVanHauwermeiren
Dan Dixey +
Daniel Frank +
Daniel Garrido +
Daniel Sakuma +
DataOmbudsman +
Dave Hirschfeld
Dave Lewis +
David Adrián Cañones Castellano +
David Arcos +
David C Hall +
David Fischer
David Hoese +
David Lutz +
David Polo +
David Stansby
Dennis Kamau +
Dillon Niederhut
Dimitri +
Dr. Irv
Dror Atariah
Eric Chea +
Eric Kisslinger
Eric O. LEBIGOT (EOL) +
FAN-GOD +
Fabian Retkowski +
Fer Sar +
Gabriel de Maeztu +
Gianpaolo Macario +
Giftlin Rajaiah
Gilberto Olimpio +
Gina +
Gjelt +
Graham Inggs +
Grant Roch
Grant Smith +
Grzegorz Konefał +
Guilherme Beltramini
HagaiHargil +
Hamish Pitkeathly +
Hammad Mashkoor +
Hannah Ferchland +
Hans
Haochen Wu +
Hissashi Rocha +
Iain Barr +
Ibrahim Sharaf ElDen +
Ignasi Fosch +
Igor Conrado Alves de Lima +
Igor Shelvinskyi +
Imanflow +
Ingolf Becker
Israel Saeta Pérez
Iva Koevska +
Jakub Nowacki +
Jan F-F +
Jan Koch +
Jan Werkmann
Janelle Zoutkamp +
Jason Bandlow +
Jaume Bonet +
Jay Alammar +
Jeff Reback
JennaVergeynst
Jimmy Woo +
Jing Qiang Goh +
Joachim Wagner +
Joan Martin Miralles +
Joel Nothman
Joeun Park +
John Cant +
Johnny Metz +
Jon Mease
Jonas Schulze +
Jongwony +
Jordi Contestí +
Joris Van den Bossche
José F. R. Fonseca +
Jovixe +
Julio Martinez +
Jörg Döpfert
KOBAYASHI Ittoku +
Kate Surta +
Kenneth +
Kevin Kuhl
Kevin Sheppard
Krzysztof Chomski
Ksenia +
Ksenia Bobrova +
Kunal Gosar +
Kurtis Kerstein +
Kyle Barron +
Laksh Arora +
Laurens Geffert +
Leif Walsh
Liam Marshall +
Liam3851 +
Licht Takeuchi
Liudmila +
Ludovico Russo +
Mabel Villalba +
Manan Pal Singh +
Manraj Singh
Marc +
Marc Garcia
Marco Hemken +
Maria del Mar Bibiloni +
Mario Corchero +
Mark Woodbridge +
Martin Journois +
Mason Gallo +
Matias Heikkilä +
Matt Braymer-Hayes
Matt Kirk +
Matt Maybeno +
Matthew Kirk +
Matthew Rocklin +
Matthew Roeschke
Matthias Bussonnier +
Max Mikhaylov +
Maxim Veksler +
Maximilian Roos
Maximiliano Greco +
Michael Penkov
Michael Röttger +
Michael Selik +
Michael Waskom
Mie~~~
Mike Kutzma +
Ming Li +
Mitar +
Mitch Negus +
Montana Low +
Moritz Münst +
Mortada Mehyar
Myles Braithwaite +
Nate Yoder
Nicholas Ursa +
Nick Chmura
Nikos Karagiannakis +
Nipun Sadvilkar +
Nis Martensen +
Noah +
Noémi Éltető +
Olivier Bilodeau +
Ondrej Kokes +
Onno Eberhard +
Paul Ganssle +
Paul Mannino +
Paul Reidy
Paulo Roberto de Oliveira Castro +
Pepe Flores +
Peter Hoffmann
Phil Ngo +
Pietro Battiston
Pranav Suri +
Priyanka Ojha +
Pulkit Maloo +
README Bot +
Ray Bell +
Riccardo Magliocchetti +
Ridhwan Luthra +
Robert Meyer
Robin
Robin Kiplang’at +
Rohan Pandit +
Rok Mihevc +
Rouz Azari
Ryszard T. Kaleta +
Sam Cohan
Sam Foo
Samir Musali +
Samuel Sinayoko +
Sangwoong Yoon
SarahJessica +
Sharad Vijalapuram +
Shubham Chaudhary +
SiYoungOh +
Sietse Brouwer
Simone Basso +
Stefania Delprete +
Stefano Cianciulli +
Stephen Childs +
StephenVoland +
Stijn Van Hoey +
Sven
Talitha Pumar +
Tarbo Fukazawa +
Ted Petrou +
Thomas A Caswell
Tim Hoffmann +
Tim Swast
Tom Augspurger
Tommy +
Tulio Casagrande +
Tushar Gupta +
Tushar Mittal +
Upkar Lidder +
Victor Villas +
Vince W +
Vinícius Figueiredo +
Vipin Kumar +
WBare
Wenhuan +
Wes Turner
William Ayd
Wilson Lin +
Xbar
Yaroslav Halchenko
Yee Mey
Yeongseon Choe +
Yian +
Yimeng Zhang
ZhuBaohe +
Zihao Zhao +
adatasetaday +
akielbowicz +
akosel +
alinde1 +
amuta +
bolkedebruin
cbertinato
cgohlke
charlie0389 +
chris-b1
csfarkas +
dajcs +
deflatSOCO +
derestle-htwg
discort
dmanikowski-reef +
donK23 +
elrubio +
fivemok +
fjdiod
fjetter +
froessler +
gabrielclow
gfyoung
ghasemnaddaf
h-vetinari +
himanshu awasthi +
ignamv +
jayfoad +
jazzmuesli +
jbrockmendel
jen w +
jjames34 +
joaoavf +
joders +
jschendel
juan huguet +
l736x +
luzpaz +
mdeboc +
miguelmorin +
miker985
miquelcamprodon +
orereta +
ottiP +
peterpanmj +
rafarui +
raph-m +
readyready15728 +
rmihael +
samghelms +
scriptomation +
sfoo +
stefansimik +
stonebig
tmnhat2001 +
tomneep +
topper-123
tv3141 +
verakai +
xpvpc +
zhanghui +