Working with missing data¶
In this section, we will discuss missing (also referred to as NA) values in pandas.
Note
The choice of using NaN internally to denote missing data was largely for simplicity and performance reasons. It differs from the MaskedArray approach of, for example, scikits.timeseries. We are hopeful that NumPy will soon be able to provide a native NA type solution (similar to R) performant enough to be used in pandas.
See the cookbook for some advanced strategies
Missing data basics¶
When / why does data become missing?¶
Some might quibble over our usage of missing. By “missing” we simply mean null or “not present for whatever reason”. Many data sets simply arrive with missing data, either because it exists and was not collected or it never existed. For example, in a collection of financial time series, some of the time series might start on different dates. Thus, values prior to the start date would generally be marked as missing.
In pandas, one of the most common ways that missing data is introduced into a data set is by reindexing. For example
In [1]: df = DataFrame(randn(5, 3), index=['a', 'c', 'e', 'f', 'h'],
...: columns=['one', 'two', 'three'])
...:
In [2]: df['four'] = 'bar'
In [3]: df['five'] = df['one'] > 0
In [4]: df
Out[4]:
one two three four five
a -1.420361 -0.015601 -1.150641 bar False
c -0.798334 -0.557697 0.381353 bar False
e 1.337122 -1.531095 1.331458 bar True
f -0.571329 -0.026671 -1.085663 bar False
h -1.114738 -0.058216 -0.486768 bar False
In [5]: df2 = df.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'])
In [6]: df2
Out[6]:
one two three four five
a -1.420361 -0.015601 -1.150641 bar False
b NaN NaN NaN NaN NaN
c -0.798334 -0.557697 0.381353 bar False
d NaN NaN NaN NaN NaN
e 1.337122 -1.531095 1.331458 bar True
f -0.571329 -0.026671 -1.085663 bar False
g NaN NaN NaN NaN NaN
h -1.114738 -0.058216 -0.486768 bar False
Values considered “missing”¶
As data comes in many shapes and forms, pandas aims to be flexible with regard to handling missing data. While NaN is the default missing value marker for reasons of computational speed and convenience, we need to be able to easily detect this value with data of different types: floating point, integer, boolean, and general object. In many cases, however, the Python None will arise and we wish to also consider that “missing” or “null”.
Until recently, for legacy reasons inf and -inf were also considered to be “null” in computations. This is no longer the case by default; use the mode.use_inf_as_null option to recover it.
To make detecting missing values easier (and across different array dtypes), pandas provides the isnull() and notnull() functions, which are also methods on Series objects:
In [7]: df2['one']
Out[7]:
a -1.420361
b NaN
c -0.798334
d NaN
e 1.337122
f -0.571329
g NaN
h -1.114738
Name: one, dtype: float64
In [8]: isnull(df2['one'])
Out[8]:
a False
b True
c False
d True
e False
f False
g True
h False
Name: one, dtype: bool
In [9]: df2['four'].notnull()
Out[9]:
a True
b False
c True
d False
e True
f True
g False
h True
Name: four, dtype: bool
Summary: NaN and None (in object arrays) are considered missing by the isnull and notnull functions. inf and -inf are no longer considered missing by default.
Datetimes¶
For datetime64[ns] types, NaT represents missing values. This is a pseudo-native sentinel value that can be represented by numpy in a singular dtype (datetime64[ns]). Pandas objects provide intercompatibility between NaT and NaN.
In [10]: df2 = df.copy()
In [11]: df2['timestamp'] = Timestamp('20120101')
In [12]: df2
Out[12]:
one two three four five timestamp
a -1.420361 -0.015601 -1.150641 bar False 2012-01-01
c -0.798334 -0.557697 0.381353 bar False 2012-01-01
e 1.337122 -1.531095 1.331458 bar True 2012-01-01
f -0.571329 -0.026671 -1.085663 bar False 2012-01-01
h -1.114738 -0.058216 -0.486768 bar False 2012-01-01
In [13]: df2.ix[['a','c','h'],['one','timestamp']] = np.nan
In [14]: df2
Out[14]:
one two three four five timestamp
a NaN -0.015601 -1.150641 bar False NaT
c NaN -0.557697 0.381353 bar False NaT
e 1.337122 -1.531095 1.331458 bar True 2012-01-01
f -0.571329 -0.026671 -1.085663 bar False 2012-01-01
h NaN -0.058216 -0.486768 bar False NaT
In [15]: df2.get_dtype_counts()
Out[15]:
bool 1
datetime64[ns] 1
float64 3
object 1
dtype: int64
Calculations with missing data¶
Missing values propagate naturally through arithmetic operations between pandas objects.
In [16]: a
Out[16]:
one two
a NaN -0.015601
c NaN -0.557697
e 1.337122 -1.531095
f -0.571329 -0.026671
h -0.571329 -0.058216
In [17]: b
Out[17]:
one two three
a NaN -0.015601 -1.150641
c NaN -0.557697 0.381353
e 1.337122 -1.531095 1.331458
f -0.571329 -0.026671 -1.085663
h NaN -0.058216 -0.486768
In [18]: a + b
Out[18]:
one three two
a NaN NaN -0.031202
c NaN NaN -1.115393
e 2.674243 NaN -3.062190
f -1.142658 NaN -0.053342
h NaN NaN -0.116432
The descriptive statistics and computational methods discussed in the data structure overview (and listed here and here) are all written to account for missing data. For example:
- When summing data, NA (missing) values will be treated as zero
- If the data are all NA, the result will be NA
- Methods like cumsum and cumprod ignore NA values, but preserve them in the resulting arrays
In [19]: df
Out[19]:
one two three
a NaN -0.015601 -1.150641
c NaN -0.557697 0.381353
e 1.337122 -1.531095 1.331458
f -0.571329 -0.026671 -1.085663
h NaN -0.058216 -0.486768
In [20]: df['one'].sum()
Out[20]: 0.76579267910953364
In [21]: df.mean(1)
Out[21]:
a -0.583121
c -0.088172
e 0.379162
f -0.561221
h -0.272492
dtype: float64
In [22]: df.cumsum()
Out[22]:
one two three
a NaN -0.015601 -1.150641
c NaN -0.573297 -0.769288
e 1.337122 -2.104392 0.562171
f 0.765793 -2.131063 -0.523492
h NaN -2.189279 -1.010260
NA values in GroupBy¶
NA groups in GroupBy are automatically excluded. This behavior is consistent with R, for example.
Cleaning / filling missing data¶
pandas objects are equipped with various data manipulation methods for dealing with missing data.
Filling missing values: fillna¶
The fillna function can “fill in” NA values with non-null data in a couple of ways, which we illustrate:
Replace NA with a scalar value
In [23]: df2
Out[23]:
one two three four five timestamp
a NaN -0.015601 -1.150641 bar False NaT
c NaN -0.557697 0.381353 bar False NaT
e 1.337122 -1.531095 1.331458 bar True 2012-01-01
f -0.571329 -0.026671 -1.085663 bar False 2012-01-01
h NaN -0.058216 -0.486768 bar False NaT
In [24]: df2.fillna(0)
Out[24]:
one two three four five timestamp
a 0.000000 -0.015601 -1.150641 bar False 1970-01-01
c 0.000000 -0.557697 0.381353 bar False 1970-01-01
e 1.337122 -1.531095 1.331458 bar True 2012-01-01
f -0.571329 -0.026671 -1.085663 bar False 2012-01-01
h 0.000000 -0.058216 -0.486768 bar False 1970-01-01
In [25]: df2['four'].fillna('missing')
Out[25]:
a bar
c bar
e bar
f bar
h bar
Name: four, dtype: object
Fill gaps forward or backward
Using the same filling arguments as reindexing, we can propagate non-null values forward or backward:
In [26]: df
Out[26]:
one two three
a NaN -0.015601 -1.150641
c NaN -0.557697 0.381353
e 1.337122 -1.531095 1.331458
f -0.571329 -0.026671 -1.085663
h NaN -0.058216 -0.486768
In [27]: df.fillna(method='pad')
Out[27]:
one two three
a NaN -0.015601 -1.150641
c NaN -0.557697 0.381353
e 1.337122 -1.531095 1.331458
f -0.571329 -0.026671 -1.085663
h -0.571329 -0.058216 -0.486768
Limit the amount of filling
If we only want consecutive gaps filled up to a certain number of data points, we can use the limit keyword:
In [28]: df
Out[28]:
one two three
a NaN -0.015601 -1.150641
c NaN -0.557697 0.381353
e NaN NaN NaN
f NaN NaN NaN
h NaN -0.058216 -0.486768
In [29]: df.fillna(method='pad', limit=1)
Out[29]:
one two three
a NaN -0.015601 -1.150641
c NaN -0.557697 0.381353
e NaN -0.557697 0.381353
f NaN NaN NaN
h NaN -0.058216 -0.486768
To remind you, these are the available filling methods:
| Method | Action |
|---|---|
| pad / ffill | Fill values forward |
| bfill / backfill | Fill values backward |
With time series data, using pad/ffill is extremely common so that the “last known value” is available at every time point.
The ffill() function is equivalent to fillna(method='ffill') and bfill() is equivalent to fillna(method='bfill')
Filling with a PandasObject¶
New in version 0.12.
You can also fillna using a dict or Series that is alignable. The labels of the dict or index of the Series must match the columns of the frame you wish to fill. The use case of this is to fill a DataFrame with the mean of that column.
In [30]: dff = DataFrame(np.random.randn(10,3),columns=list('ABC'))
In [31]: dff.iloc[3:5,0] = np.nan
In [32]: dff.iloc[4:6,1] = np.nan
In [33]: dff.iloc[5:8,2] = np.nan
In [34]: dff
Out[34]:
A B C
0 1.685148 0.112572 -1.495309
1 0.898435 -0.148217 -1.596070
2 0.159653 0.262136 0.036220
3 NaN -0.255069 -0.271020
4 NaN NaN -1.165787
5 0.846974 NaN NaN
6 -0.303961 0.625555 NaN
7 0.249698 1.103949 NaN
8 1.998044 -0.244548 0.136235
9 0.886313 -1.350722 -0.886348
In [35]: dff.fillna(dff.mean())
Out[35]:
A B C
0 1.685148 0.112572 -1.495309
1 0.898435 -0.148217 -1.596070
2 0.159653 0.262136 0.036220
3 0.802538 -0.255069 -0.271020
4 0.802538 0.013207 -1.165787
5 0.846974 0.013207 -0.748868
6 -0.303961 0.625555 -0.748868
7 0.249698 1.103949 -0.748868
8 1.998044 -0.244548 0.136235
9 0.886313 -1.350722 -0.886348
In [36]: dff.fillna(dff.mean()['B':'C'])
Out[36]:
A B C
0 1.685148 0.112572 -1.495309
1 0.898435 -0.148217 -1.596070
2 0.159653 0.262136 0.036220
3 NaN -0.255069 -0.271020
4 NaN 0.013207 -1.165787
5 0.846974 0.013207 -0.748868
6 -0.303961 0.625555 -0.748868
7 0.249698 1.103949 -0.748868
8 1.998044 -0.244548 0.136235
9 0.886313 -1.350722 -0.886348
New in version 0.13.
Same result as above, but is aligning the ‘fill’ value which is a Series in this case.
In [37]: dff.where(notnull(dff),dff.mean(),axis='columns')
Out[37]:
A B C
0 1.685148 0.112572 -1.495309
1 0.898435 -0.148217 -1.596070
2 0.159653 0.262136 0.036220
3 0.802538 -0.255069 -0.271020
4 0.802538 0.013207 -1.165787
5 0.846974 0.013207 -0.748868
6 -0.303961 0.625555 -0.748868
7 0.249698 1.103949 -0.748868
8 1.998044 -0.244548 0.136235
9 0.886313 -1.350722 -0.886348
Dropping axis labels with missing data: dropna¶
You may wish to simply exclude labels from a data set which refer to missing data. To do this, use the dropna method:
In [38]: df
Out[38]:
one two three
a NaN -0.015601 -1.150641
c NaN -0.557697 0.381353
e NaN 0.000000 0.000000
f NaN 0.000000 0.000000
h NaN -0.058216 -0.486768
In [39]: df.dropna(axis=0)
Out[39]:
Empty DataFrame
Columns: [one, two, three]
Index: []
In [40]: df.dropna(axis=1)
Out[40]:
two three
a -0.015601 -1.150641
c -0.557697 0.381353
e 0.000000 0.000000
f 0.000000 0.000000
h -0.058216 -0.486768
In [41]: df['one'].dropna()
Out[41]: Series([], name: one, dtype: float64)
dropna is presently only implemented for Series and DataFrame, but will be eventually added to Panel. Series.dropna is a simpler method as it only has one axis to consider. DataFrame.dropna has considerably more options, which can be examined in the API.
Interpolation¶
New in version 0.13.0.
Both Series and Dataframe objects have an interpolate method that, by default, performs linear interpolation at missing datapoints.
In [42]: ts
Out[42]:
2000-01-31 0.469112
2000-02-29 NaN
2000-03-31 NaN
2000-04-28 NaN
2000-05-31 NaN
...
2007-11-30 -5.485119
2007-12-31 -6.854968
2008-01-31 -7.809176
2008-02-29 -6.346480
2008-03-31 -8.089641
2008-04-30 -8.916232
Freq: BM, Length: 100
In [43]: ts.count()
Out[43]: 61
In [44]: ts.interpolate().count()
Out[44]: 100
In [45]: plt.figure()
Out[45]: <matplotlib.figure.Figure at 0xa9ea80ec>
In [46]: ts.interpolate().plot()
Out[46]: <matplotlib.axes.AxesSubplot at 0xa8c532ec>
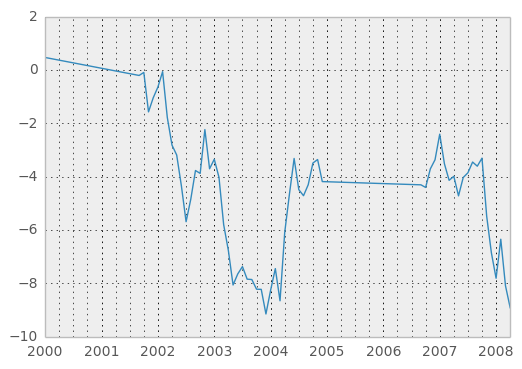
Index aware interpolation is available via the method keyword:
In [47]: ts2
Out[47]:
2000-01-31 0.469112
2000-02-29 NaN
2002-07-31 -5.689738
2005-01-31 NaN
2008-04-30 -8.916232
dtype: float64
In [48]: ts2.interpolate()
Out[48]:
2000-01-31 0.469112
2000-02-29 -2.610313
2002-07-31 -5.689738
2005-01-31 -7.302985
2008-04-30 -8.916232
dtype: float64
In [49]: ts2.interpolate(method='time')
Out[49]:
2000-01-31 0.469112
2000-02-29 0.273272
2002-07-31 -5.689738
2005-01-31 -7.095568
2008-04-30 -8.916232
dtype: float64
For a floating-point index, use method='values':
In [50]: ser
Out[50]:
0 0
1 NaN
10 10
dtype: float64
In [51]: ser.interpolate()
Out[51]:
0 0
1 5
10 10
dtype: float64
In [52]: ser.interpolate(method='values')
Out[52]:
0 0
1 1
10 10
dtype: float64
You can also interpolate with a DataFrame:
In [53]: df = DataFrame({'A': [1, 2.1, np.nan, 4.7, 5.6, 6.8],
....: 'B': [.25, np.nan, np.nan, 4, 12.2, 14.4]})
....:
In [54]: df
Out[54]:
A B
0 1.0 0.25
1 2.1 NaN
2 NaN NaN
3 4.7 4.00
4 5.6 12.20
5 6.8 14.40
In [55]: df.interpolate()
Out[55]:
A B
0 1.0 0.25
1 2.1 1.50
2 3.4 2.75
3 4.7 4.00
4 5.6 12.20
5 6.8 14.40
The method argument gives access to fancier interpolation methods. If you have scipy installed, you can set pass the name of a 1-d interpolation routine to method. You’ll want to consult the full scipy interpolation documentation and reference guide for details. The appropriate interpolation method will depend on the type of data you are working with. For example, if you are dealing with a time series that is growing at an increasing rate, method='quadratic' may be appropriate. If you have values approximating a cumulative distribution function, then method='pchip' should work well.
Warning
These methods require scipy.
In [56]: df.interpolate(method='barycentric')
Out[56]:
A B
0 1.00 0.250
1 2.10 -7.660
2 3.53 -4.515
3 4.70 4.000
4 5.60 12.200
5 6.80 14.400
In [57]: df.interpolate(method='pchip')
Out[57]:
A B
0 1.000000 0.250000
1 2.100000 1.130135
2 3.429309 2.337586
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
When interpolating via a polynomial or spline approximation, you must also specify the degree or order of the approximation:
In [58]: df.interpolate(method='spline', order=2)
Out[58]:
A B
0 1.000000 0.250000
1 2.100000 -0.428598
2 3.404545 1.206900
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
In [59]: df.interpolate(method='polynomial', order=2)
Out[59]:
A B
0 1.000000 0.250000
1 2.100000 -4.161538
2 3.547059 -2.911538
3 4.700000 4.000000
4 5.600000 12.200000
5 6.800000 14.400000
Compare several methods:
In [60]: np.random.seed(2)
In [61]: ser = Series(np.arange(1, 10.1, .25)**2 + np.random.randn(37))
In [62]: bad = np.array([4, 13, 14, 15, 16, 17, 18, 20, 29])
In [63]: ser[bad] = np.nan
In [64]: methods = ['linear', 'quadratic', 'cubic']
In [65]: df = DataFrame({m: ser.interpolate(method=m) for m in methods})
In [66]: plt.figure()
Out[66]: <matplotlib.figure.Figure at 0xa9ec950c>
In [67]: df.plot()
Out[67]: <matplotlib.axes.AxesSubplot at 0xaa050c4c>
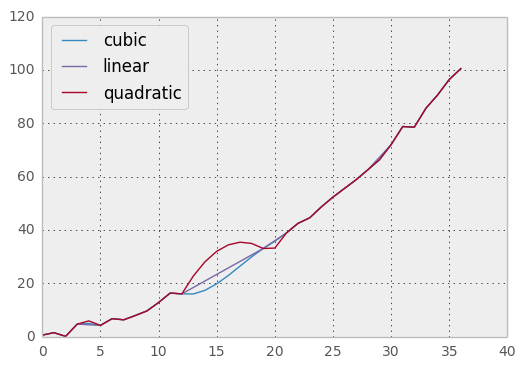
Another use case is interpolation at new values. Suppose you have 100 observations from some distribution. And let’s suppose that you’re particularly interested in what’s happening around the middle. You can mix pandas’ reindex and interpolate methods to interpolate at the new values.
In [68]: ser = Series(np.sort(np.random.uniform(size=100)))
# interpolate at new_index
In [69]: new_index = ser.index + Index([49.25, 49.5, 49.75, 50.25, 50.5, 50.75])
In [70]: interp_s = ser.reindex(new_index).interpolate(method='pchip')
In [71]: interp_s[49:51]
Out[71]:
49.00 0.471410
49.25 0.476841
49.50 0.481780
49.75 0.485998
50.00 0.489266
50.25 0.491814
50.50 0.493995
50.75 0.495763
51.00 0.497074
dtype: float64
Like other pandas fill methods, interpolate accepts a limit keyword argument. Use this to limit the number of consecutive interpolations, keeping NaN values for interpolations that are too far from the last valid observation:
In [72]: ser = Series([1, 3, np.nan, np.nan, np.nan, 11])
In [73]: ser.interpolate(limit=2)
Out[73]:
0 1
1 3
2 5
3 7
4 NaN
5 11
dtype: float64
Replacing Generic Values¶
Often times we want to replace arbitrary values with other values. New in v0.8 is the replace method in Series/DataFrame that provides an efficient yet flexible way to perform such replacements.
For a Series, you can replace a single value or a list of values by another value:
In [74]: ser = Series([0., 1., 2., 3., 4.])
In [75]: ser.replace(0, 5)
Out[75]:
0 5
1 1
2 2
3 3
4 4
dtype: float64
You can replace a list of values by a list of other values:
In [76]: ser.replace([0, 1, 2, 3, 4], [4, 3, 2, 1, 0])
Out[76]:
0 4
1 3
2 2
3 1
4 0
dtype: float64
You can also specify a mapping dict:
In [77]: ser.replace({0: 10, 1: 100})
Out[77]:
0 10
1 100
2 2
3 3
4 4
dtype: float64
For a DataFrame, you can specify individual values by column:
In [78]: df = DataFrame({'a': [0, 1, 2, 3, 4], 'b': [5, 6, 7, 8, 9]})
In [79]: df.replace({'a': 0, 'b': 5}, 100)
Out[79]:
a b
0 100 100
1 1 6
2 2 7
3 3 8
4 4 9
Instead of replacing with specified values, you can treat all given values as missing and interpolate over them:
In [80]: ser.replace([1, 2, 3], method='pad')
Out[80]:
0 0
1 0
2 0
3 0
4 4
dtype: float64
String/Regular Expression Replacement¶
Note
Python strings prefixed with the r character such as r'hello world' are so-called “raw” strings. They have different semantics regarding backslashes than strings without this prefix. Backslashes in raw strings will be interpreted as an escaped backslash, e.g., r'\' == '\\'. You should read about them if this is unclear.
Replace the ‘.’ with nan (str -> str)
In [81]: d = {'a': list(range(4)), 'b': list('ab..'), 'c': ['a', 'b', nan, 'd']}
In [82]: df = DataFrame(d)
In [83]: df.replace('.', nan)
Out[83]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
Now do it with a regular expression that removes surrounding whitespace (regex -> regex)
In [84]: df.replace(r'\s*\.\s*', nan, regex=True)
Out[84]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
Replace a few different values (list -> list)
In [85]: df.replace(['a', '.'], ['b', nan])
Out[85]:
a b c
0 0 b b
1 1 b b
2 2 NaN NaN
3 3 NaN d
list of regex -> list of regex
In [86]: df.replace([r'\.', r'(a)'], ['dot', '\1stuff'], regex=True)
Out[86]:
a b c
0 0 stuff stuff
1 1 b b
2 2 dot NaN
3 3 dot d
Only search in column 'b' (dict -> dict)
In [87]: df.replace({'b': '.'}, {'b': nan})
Out[87]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
Same as the previous example, but use a regular expression for searching instead (dict of regex -> dict)
In [88]: df.replace({'b': r'\s*\.\s*'}, {'b': nan}, regex=True)
Out[88]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
You can pass nested dictionaries of regular expressions that use regex=True
In [89]: df.replace({'b': {'b': r''}}, regex=True)
Out[89]:
a b c
0 0 a a
1 1 b
2 2 . NaN
3 3 . d
or you can pass the nested dictionary like so
In [90]: df.replace(regex={'b': {r'\s*\.\s*': nan}})
Out[90]:
a b c
0 0 a a
1 1 b b
2 2 NaN NaN
3 3 NaN d
You can also use the group of a regular expression match when replacing (dict of regex -> dict of regex), this works for lists as well
In [91]: df.replace({'b': r'\s*(\.)\s*'}, {'b': r'\1ty'}, regex=True)
Out[91]:
a b c
0 0 a a
1 1 b b
2 2 .ty NaN
3 3 .ty d
You can pass a list of regular expressions, of which those that match will be replaced with a scalar (list of regex -> regex)
In [92]: df.replace([r'\s*\.\s*', r'a|b'], nan, regex=True)
Out[92]:
a b c
0 0 NaN NaN
1 1 NaN NaN
2 2 NaN NaN
3 3 NaN d
All of the regular expression examples can also be passed with the to_replace argument as the regex argument. In this case the value argument must be passed explicity by name or regex must be a nested dictionary. The previous example, in this case, would then be
In [93]: df.replace(regex=[r'\s*\.\s*', r'a|b'], value=nan)
Out[93]:
a b c
0 0 NaN NaN
1 1 NaN NaN
2 2 NaN NaN
3 3 NaN d
This can be convenient if you do not want to pass regex=True every time you want to use a regular expression.
Note
Anywhere in the above replace examples that you see a regular expression a compiled regular expression is valid as well.
Numeric Replacement¶
Similiar to DataFrame.fillna
In [94]: df = DataFrame(randn(10, 2))
In [95]: df[rand(df.shape[0]) > 0.5] = 1.5
In [96]: df.replace(1.5, nan)
Out[96]:
0 1
0 -0.844214 -1.021415
1 0.432396 -0.323580
2 0.423825 0.799180
3 1.262614 0.751965
4 NaN NaN
5 NaN NaN
6 -0.498174 -1.060799
7 0.591667 -0.183257
8 1.019855 -1.482465
9 NaN NaN
Replacing more than one value via lists works as well
In [97]: df00 = df.values[0, 0]
In [98]: df.replace([1.5, df00], [nan, 'a'])
Out[98]:
0 1
0 a -1.021415
1 0.4323957 -0.323580
2 0.4238247 0.799180
3 1.262614 0.751965
4 NaN NaN
5 NaN NaN
6 -0.4981742 -1.060799
7 0.5916665 -0.183257
8 1.019855 -1.482465
9 NaN NaN
In [99]: df[1].dtype
Out[99]: dtype('float64')
You can also operate on the DataFrame in place
In [100]: df.replace(1.5, nan, inplace=True)
Warning
When replacing multiple bool or datetime64 objects, the first argument to replace (to_replace) must match the type of the value being replaced type. For example,
s = Series([True, False, True])
s.replace({'a string': 'new value', True: False}) # raises
TypeError: Cannot compare types 'ndarray(dtype=bool)' and 'str'
will raise a TypeError because one of the dict keys is not of the correct type for replacement.
However, when replacing a single object such as,
In [101]: s = Series([True, False, True])
In [102]: s.replace('a string', 'another string')
Out[102]:
0 True
1 False
2 True
dtype: bool
the original NDFrame object will be returned untouched. We’re working on unifying this API, but for backwards compatibility reasons we cannot break the latter behavior. See GH6354 for more details.
Missing data casting rules and indexing¶
While pandas supports storing arrays of integer and boolean type, these types are not capable of storing missing data. Until we can switch to using a native NA type in NumPy, we’ve established some “casting rules” when reindexing will cause missing data to be introduced into, say, a Series or DataFrame. Here they are:
| data type | Cast to |
|---|---|
| integer | float |
| boolean | object |
| float | no cast |
| object | no cast |
For example:
In [103]: s = Series(randn(5), index=[0, 2, 4, 6, 7])
In [104]: s > 0
Out[104]:
0 True
2 True
4 True
6 True
7 True
dtype: bool
In [105]: (s > 0).dtype
Out[105]: dtype('bool')
In [106]: crit = (s > 0).reindex(list(range(8)))
In [107]: crit
Out[107]:
0 True
1 NaN
2 True
3 NaN
4 True
5 NaN
6 True
7 True
dtype: object
In [108]: crit.dtype
Out[108]: dtype('O')
Ordinarily NumPy will complain if you try to use an object array (even if it contains boolean values) instead of a boolean array to get or set values from an ndarray (e.g. selecting values based on some criteria). If a boolean vector contains NAs, an exception will be generated:
In [109]: reindexed = s.reindex(list(range(8))).fillna(0)
In [110]: reindexed[crit]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-110-2da204ed1ac7> in <module>()
----> 1 reindexed[crit]
/home/joris/scipy/pandas/pandas/core/series.pyc in __getitem__(self, key)
514 key = list(key)
515
--> 516 if _is_bool_indexer(key):
517 key = _check_bool_indexer(self.index, key)
518
/home/joris/scipy/pandas/pandas/core/common.pyc in _is_bool_indexer(key)
1811 if not lib.is_bool_array(key):
1812 if isnull(key).any():
-> 1813 raise ValueError('cannot index with vector containing '
1814 'NA / NaN values')
1815 return False
ValueError: cannot index with vector containing NA / NaN values
However, these can be filled in using fillna and it will work fine:
In [111]: reindexed[crit.fillna(False)]
Out[111]:
0 0.126504
2 0.696198
4 0.697416
6 0.601516
7 0.003659
dtype: float64
In [112]: reindexed[crit.fillna(True)]
Out[112]:
0 0.126504
1 0.000000
2 0.696198
3 0.000000
4 0.697416
5 0.000000
6 0.601516
7 0.003659
dtype: float64