Essential Basic Functionality¶
Here we discuss a lot of the essential functionality common to the pandas data structures. Here’s how to create some of the objects used in the examples from the previous section:
In [1]: index = date_range('1/1/2000', periods=8)
In [2]: s = Series(randn(5), index=['a', 'b', 'c', 'd', 'e'])
In [3]: df = DataFrame(randn(8, 3), index=index,
...: columns=['A', 'B', 'C'])
...:
In [4]: wp = Panel(randn(2, 5, 4), items=['Item1', 'Item2'],
...: major_axis=date_range('1/1/2000', periods=5),
...: minor_axis=['A', 'B', 'C', 'D'])
...:
Head and Tail¶
To view a small sample of a Series or DataFrame object, use the head() and tail() methods. The default number of elements to display is five, but you may pass a custom number.
In [5]: long_series = Series(randn(1000))
In [6]: long_series.head()
Out[6]:
0 -0.305384
1 -0.479195
2 0.095031
3 -0.270099
4 -0.707140
dtype: float64
In [7]: long_series.tail(3)
Out[7]:
997 0.588446
998 0.026465
999 -1.728222
dtype: float64
Attributes and the raw ndarray(s)¶
pandas objects have a number of attributes enabling you to access the metadata
- shape: gives the axis dimensions of the object, consistent with ndarray
- Axis labels
- Series: index (only axis)
- DataFrame: index (rows) and columns
- Panel: items, major_axis, and minor_axis
Note, these attributes can be safely assigned to!
In [8]: df[:2]
Out[8]:
A B C
2000-01-01 0.187483 -1.933946 0.377312
2000-01-02 0.734122 2.141616 -0.011225
In [9]: df.columns = [x.lower() for x in df.columns]
In [10]: df
Out[10]:
a b c
2000-01-01 0.187483 -1.933946 0.377312
2000-01-02 0.734122 2.141616 -0.011225
2000-01-03 0.048869 -1.360687 -0.479010
2000-01-04 -0.859661 -0.231595 -0.527750
2000-01-05 -1.296337 0.150680 0.123836
2000-01-06 0.571764 1.555563 -0.823761
2000-01-07 0.535420 -1.032853 1.469725
2000-01-08 1.304124 1.449735 0.203109
To get the actual data inside a data structure, one need only access the values property:
In [11]: s.values
Out[11]: array([ 0.1122, 0.8717, -0.8161, -0.7849, 1.0307])
In [12]: df.values
Out[12]:
array([[ 0.1875, -1.9339, 0.3773],
[ 0.7341, 2.1416, -0.0112],
[ 0.0489, -1.3607, -0.479 ],
[-0.8597, -0.2316, -0.5278],
[-1.2963, 0.1507, 0.1238],
[ 0.5718, 1.5556, -0.8238],
[ 0.5354, -1.0329, 1.4697],
[ 1.3041, 1.4497, 0.2031]])
In [13]: wp.values
Out[13]:
array([[[-1.032 , 0.9698, -0.9627, 1.3821],
[-0.9388, 0.6691, -0.4336, -0.2736],
[ 0.6804, -0.3084, -0.2761, -1.8212],
[-1.9936, -1.9274, -2.0279, 1.625 ],
[ 0.5511, 3.0593, 0.4553, -0.0307]],
[[ 0.9357, 1.0612, -2.1079, 0.1999],
[ 0.3236, -0.6416, -0.5875, 0.0539],
[ 0.1949, -0.382 , 0.3186, 2.0891],
[-0.7283, -0.0903, -0.7482, 1.3189],
[-2.0298, 0.7927, 0.461 , -0.5427]]])
If a DataFrame or Panel contains homogeneously-typed data, the ndarray can actually be modified in-place, and the changes will be reflected in the data structure. For heterogeneous data (e.g. some of the DataFrame’s columns are not all the same dtype), this will not be the case. The values attribute itself, unlike the axis labels, cannot be assigned to.
Note
When working with heterogeneous data, the dtype of the resulting ndarray will be chosen to accommodate all of the data involved. For example, if strings are involved, the result will be of object dtype. If there are only floats and integers, the resulting array will be of float dtype.
Accelerated operations¶
pandas has support for accelerating certain types of binary numerical and boolean operations using the numexpr library (starting in 0.11.0) and the bottleneck libraries.
These libraries are especially useful when dealing with large data sets, and provide large speedups. numexpr uses smart chunking, caching, and multiple cores. bottleneck is a set of specialized cython routines that are especially fast when dealing with arrays that have nans.
Here is a sample (using 100 column x 100,000 row DataFrames):
| Operation | 0.11.0 (ms) | Prior Version (ms) | Ratio to Prior |
|---|---|---|---|
| df1 > df2 | 13.32 | 125.35 | 0.1063 |
| df1 * df2 | 21.71 | 36.63 | 0.5928 |
| df1 + df2 | 22.04 | 36.50 | 0.6039 |
You are highly encouraged to install both libraries. See the section Recommended Dependencies for more installation info.
Flexible binary operations¶
With binary operations between pandas data structures, there are two key points of interest:
- Broadcasting behavior between higher- (e.g. DataFrame) and lower-dimensional (e.g. Series) objects.
- Missing data in computations
We will demonstrate how to manage these issues independently, though they can be handled simultaneously.
Matching / broadcasting behavior¶
DataFrame has the methods add(), sub(), mul(), div() and related functions radd(), rsub(), ... for carrying out binary operations. For broadcasting behavior, Series input is of primary interest. Using these functions, you can use to either match on the index or columns via the axis keyword:
In [14]: df = DataFrame({'one' : Series(randn(3), index=['a', 'b', 'c']),
....: 'two' : Series(randn(4), index=['a', 'b', 'c', 'd']),
....: 'three' : Series(randn(3), index=['b', 'c', 'd'])})
....:
In [15]: df
Out[15]:
one three two
a -0.626544 NaN -0.351587
b -0.138894 -0.177289 1.136249
c 0.011617 0.462215 -0.448789
d NaN 1.124472 -1.101558
In [16]: row = df.ix[1]
In [17]: column = df['two']
In [18]: df.sub(row, axis='columns')
Out[18]:
one three two
a -0.487650 NaN -1.487837
b 0.000000 0.000000 0.000000
c 0.150512 0.639504 -1.585038
d NaN 1.301762 -2.237808
In [19]: df.sub(row, axis=1)
Out[19]:
one three two
a -0.487650 NaN -1.487837
b 0.000000 0.000000 0.000000
c 0.150512 0.639504 -1.585038
d NaN 1.301762 -2.237808
In [20]: df.sub(column, axis='index')
Out[20]:
one three two
a -0.274957 NaN 0
b -1.275144 -1.313539 0
c 0.460406 0.911003 0
d NaN 2.226031 0
In [21]: df.sub(column, axis=0)
Out[21]:
one three two
a -0.274957 NaN 0
b -1.275144 -1.313539 0
c 0.460406 0.911003 0
d NaN 2.226031 0
Furthermore you can align a level of a multi-indexed DataFrame with a Series.
In [22]: dfmi = df.copy()
In [23]: dfmi.index = MultiIndex.from_tuples([(1,'a'),(1,'b'),(1,'c'),(2,'a')],
....: names=['first','second'])
....:
In [24]: dfmi.sub(column, axis=0, level='second')
Out[24]:
one three two
first second
1 a -0.274957 NaN 0.000000
b -1.275144 -1.313539 0.000000
c 0.460406 0.911003 0.000000
2 a NaN 1.476060 -0.749971
With Panel, describing the matching behavior is a bit more difficult, so the arithmetic methods instead (and perhaps confusingly?) give you the option to specify the broadcast axis. For example, suppose we wished to demean the data over a particular axis. This can be accomplished by taking the mean over an axis and broadcasting over the same axis:
In [25]: major_mean = wp.mean(axis='major')
In [26]: major_mean
Out[26]:
Item1 Item2
A -0.546569 -0.260774
B 0.492478 0.147993
C -0.649010 -0.532794
D 0.176307 0.623812
In [27]: wp.sub(major_mean, axis='major')
Out[27]:
<class 'pandas.core.panel.Panel'>
Dimensions: 2 (items) x 5 (major_axis) x 4 (minor_axis)
Items axis: Item1 to Item2
Major_axis axis: 2000-01-01 00:00:00 to 2000-01-05 00:00:00
Minor_axis axis: A to D
And similarly for axis="items" and axis="minor".
Note
I could be convinced to make the axis argument in the DataFrame methods match the broadcasting behavior of Panel. Though it would require a transition period so users can change their code...
Missing data / operations with fill values¶
In Series and DataFrame (though not yet in Panel), the arithmetic functions have the option of inputting a fill_value, namely a value to substitute when at most one of the values at a location are missing. For example, when adding two DataFrame objects, you may wish to treat NaN as 0 unless both DataFrames are missing that value, in which case the result will be NaN (you can later replace NaN with some other value using fillna if you wish).
In [28]: df
Out[28]:
one three two
a -0.626544 NaN -0.351587
b -0.138894 -0.177289 1.136249
c 0.011617 0.462215 -0.448789
d NaN 1.124472 -1.101558
In [29]: df2
Out[29]:
one three two
a -0.626544 1.000000 -0.351587
b -0.138894 -0.177289 1.136249
c 0.011617 0.462215 -0.448789
d NaN 1.124472 -1.101558
In [30]: df + df2
Out[30]:
one three two
a -1.253088 NaN -0.703174
b -0.277789 -0.354579 2.272499
c 0.023235 0.924429 -0.897577
d NaN 2.248945 -2.203116
In [31]: df.add(df2, fill_value=0)
Out[31]:
one three two
a -1.253088 1.000000 -0.703174
b -0.277789 -0.354579 2.272499
c 0.023235 0.924429 -0.897577
d NaN 2.248945 -2.203116
Flexible Comparisons¶
Starting in v0.8, pandas introduced binary comparison methods eq, ne, lt, gt, le, and ge to Series and DataFrame whose behavior is analogous to the binary arithmetic operations described above:
In [32]: df.gt(df2)
Out[32]:
one three two
a False False False
b False False False
c False False False
d False False False
In [33]: df2.ne(df)
Out[33]:
one three two
a False True False
b False False False
c False False False
d True False False
These operations produce a pandas object the same type as the left-hand-side input that if of dtype bool. These boolean objects can be used in indexing operations, see here
Boolean Reductions¶
You can apply the reductions: empty, any(), all(), and bool() to provide a way to summarize a boolean result.
In [34]: (df>0).all()
Out[34]:
one False
three False
two False
dtype: bool
In [35]: (df>0).any()
Out[35]:
one True
three True
two True
dtype: bool
You can reduce to a final boolean value.
In [36]: (df>0).any().any()
Out[36]: True
You can test if a pandas object is empty, via the empty property.
In [37]: df.empty
Out[37]: False
In [38]: DataFrame(columns=list('ABC')).empty
Out[38]: True
To evaluate single-element pandas objects in a boolean context, use the method bool():
In [39]: Series([True]).bool()
Out[39]: True
In [40]: Series([False]).bool()
Out[40]: False
In [41]: DataFrame([[True]]).bool()
Out[41]: True
In [42]: DataFrame([[False]]).bool()
Out[42]: False
Warning
You might be tempted to do the following:
>>>if df:
...
Or
>>> df and df2
These both will raise as you are trying to compare multiple values.
ValueError: The truth value of an array is ambiguous. Use a.empty, a.any() or a.all().
See gotchas for a more detailed discussion.
Comparing if objects are equivalent¶
Often you may find there is more than one way to compute the same result. As a simple example, consider df+df and df*2. To test that these two computations produce the same result, given the tools shown above, you might imagine using (df+df == df*2).all(). But in fact, this expression is False:
In [43]: df+df == df*2
Out[43]:
one three two
a True False True
b True True True
c True True True
d False True True
In [44]: (df+df == df*2).all()
Out[44]:
one False
three False
two True
dtype: bool
Notice that the boolean DataFrame df+df == df*2 contains some False values! That is because NaNs do not compare as equals:
In [45]: np.nan == np.nan
Out[45]: False
So, as of v0.13.1, NDFrames (such as Series, DataFrames, and Panels) have an equals() method for testing equality, with NaNs in corresponding locations treated as equal.
In [46]: (df+df).equals(df*2)
Out[46]: True
Note that the Series or DataFrame index needs to be in the same order for equality to be True:
In [47]: df1 = DataFrame({'col':['foo', 0, np.nan]})
In [48]: df2 = DataFrame({'col':[np.nan, 0, 'foo']}, index=[2,1,0])
In [49]: df1.equals(df2)
Out[49]: False
In [50]: df1.equals(df2.sort())
Out[50]: True
Combining overlapping data sets¶
A problem occasionally arising is the combination of two similar data sets where values in one are preferred over the other. An example would be two data series representing a particular economic indicator where one is considered to be of “higher quality”. However, the lower quality series might extend further back in history or have more complete data coverage. As such, we would like to combine two DataFrame objects where missing values in one DataFrame are conditionally filled with like-labeled values from the other DataFrame. The function implementing this operation is combine_first(), which we illustrate:
In [51]: df1 = DataFrame({'A' : [1., np.nan, 3., 5., np.nan],
....: 'B' : [np.nan, 2., 3., np.nan, 6.]})
....:
In [52]: df2 = DataFrame({'A' : [5., 2., 4., np.nan, 3., 7.],
....: 'B' : [np.nan, np.nan, 3., 4., 6., 8.]})
....:
In [53]: df1
Out[53]:
A B
0 1 NaN
1 NaN 2
2 3 3
3 5 NaN
4 NaN 6
In [54]: df2
Out[54]:
A B
0 5 NaN
1 2 NaN
2 4 3
3 NaN 4
4 3 6
5 7 8
In [55]: df1.combine_first(df2)
Out[55]:
A B
0 1 NaN
1 2 2
2 3 3
3 5 4
4 3 6
5 7 8
General DataFrame Combine¶
The combine_first() method above calls the more general DataFrame method combine(). This method takes another DataFrame and a combiner function, aligns the input DataFrame and then passes the combiner function pairs of Series (i.e., columns whose names are the same).
So, for instance, to reproduce combine_first() as above:
In [56]: combiner = lambda x, y: np.where(isnull(x), y, x)
In [57]: df1.combine(df2, combiner)
Out[57]:
A B
0 1 NaN
1 2 2
2 3 3
3 5 4
4 3 6
5 7 8
Descriptive statistics¶
A large number of methods for computing descriptive statistics and other related operations on Series, DataFrame, and Panel. Most of these are aggregations (hence producing a lower-dimensional result) like sum(), mean(), and quantile(), but some of them, like cumsum() and cumprod(), produce an object of the same size. Generally speaking, these methods take an axis argument, just like ndarray.{sum, std, ...}, but the axis can be specified by name or integer:
- Series: no axis argument needed
- DataFrame: “index” (axis=0, default), “columns” (axis=1)
- Panel: “items” (axis=0), “major” (axis=1, default), “minor” (axis=2)
For example:
In [58]: df
Out[58]:
one three two
a -0.626544 NaN -0.351587
b -0.138894 -0.177289 1.136249
c 0.011617 0.462215 -0.448789
d NaN 1.124472 -1.101558
In [59]: df.mean(0)
Out[59]:
one -0.251274
three 0.469799
two -0.191421
dtype: float64
In [60]: df.mean(1)
Out[60]:
a -0.489066
b 0.273355
c 0.008348
d 0.011457
dtype: float64
All such methods have a skipna option signaling whether to exclude missing data (True by default):
In [61]: df.sum(0, skipna=False)
Out[61]:
one NaN
three NaN
two -0.765684
dtype: float64
In [62]: df.sum(axis=1, skipna=True)
Out[62]:
a -0.978131
b 0.820066
c 0.025044
d 0.022914
dtype: float64
Combined with the broadcasting / arithmetic behavior, one can describe various statistical procedures, like standardization (rendering data zero mean and standard deviation 1), very concisely:
In [63]: ts_stand = (df - df.mean()) / df.std()
In [64]: ts_stand.std()
Out[64]:
one 1
three 1
two 1
dtype: float64
In [65]: xs_stand = df.sub(df.mean(1), axis=0).div(df.std(1), axis=0)
In [66]: xs_stand.std(1)
Out[66]:
a 1
b 1
c 1
d 1
dtype: float64
Note that methods like cumsum() and cumprod() preserve the location of NA values:
In [67]: df.cumsum()
Out[67]:
one three two
a -0.626544 NaN -0.351587
b -0.765438 -0.177289 0.784662
c -0.753821 0.284925 0.335874
d NaN 1.409398 -0.765684
Here is a quick reference summary table of common functions. Each also takes an optional level parameter which applies only if the object has a hierarchical index.
| Function | Description |
|---|---|
| count | Number of non-null observations |
| sum | Sum of values |
| mean | Mean of values |
| mad | Mean absolute deviation |
| median | Arithmetic median of values |
| min | Minimum |
| max | Maximum |
| mode | Mode |
| abs | Absolute Value |
| prod | Product of values |
| std | Unbiased standard deviation |
| var | Unbiased variance |
| sem | Unbiased standard error of the mean |
| skew | Unbiased skewness (3rd moment) |
| kurt | Unbiased kurtosis (4th moment) |
| quantile | Sample quantile (value at %) |
| cumsum | Cumulative sum |
| cumprod | Cumulative product |
| cummax | Cumulative maximum |
| cummin | Cumulative minimum |
Note that by chance some NumPy methods, like mean, std, and sum, will exclude NAs on Series input by default:
In [68]: np.mean(df['one'])
Out[68]: -0.25127365175839511
In [69]: np.mean(df['one'].values)
Out[69]: nan
Series also has a method nunique() which will return the number of unique non-null values:
In [70]: series = Series(randn(500))
In [71]: series[20:500] = np.nan
In [72]: series[10:20] = 5
In [73]: series.nunique()
Out[73]: 11
Summarizing data: describe¶
There is a convenient describe() function which computes a variety of summary statistics about a Series or the columns of a DataFrame (excluding NAs of course):
In [74]: series = Series(randn(1000))
In [75]: series[::2] = np.nan
In [76]: series.describe()
Out[76]:
count 500.000000
mean -0.039663
std 1.069371
min -3.463789
25% -0.731101
50% -0.058918
75% 0.672758
max 3.120271
dtype: float64
In [77]: frame = DataFrame(randn(1000, 5), columns=['a', 'b', 'c', 'd', 'e'])
In [78]: frame.ix[::2] = np.nan
In [79]: frame.describe()
Out[79]:
a b c d e
count 500.000000 500.000000 500.000000 500.000000 500.000000
mean 0.000954 -0.044014 0.075936 -0.003679 0.020751
std 1.005133 0.974882 0.967432 1.004732 0.963812
min -3.010899 -2.782760 -3.401252 -2.944925 -3.794127
25% -0.682900 -0.681161 -0.528190 -0.663503 -0.615717
50% -0.001651 -0.006279 0.040098 -0.003378 0.006282
75% 0.656439 0.632852 0.717919 0.687214 0.653423
max 3.007143 2.627688 2.702490 2.850852 3.072117
You can select specific percentiles to include in the output:
In [80]: series.describe(percentiles=[.05, .25, .75, .95])
Out[80]:
count 500.000000
mean -0.039663
std 1.069371
min -3.463789
5% -1.741334
25% -0.731101
50% -0.058918
75% 0.672758
95% 1.854383
max 3.120271
dtype: float64
By default, the median is always included.
For a non-numerical Series object, describe() will give a simple summary of the number of unique values and most frequently occurring values:
In [81]: s = Series(['a', 'a', 'b', 'b', 'a', 'a', np.nan, 'c', 'd', 'a'])
In [82]: s.describe()
Out[82]:
count 9
unique 4
top a
freq 5
dtype: object
Note that on a mixed-type DataFrame object, describe() will restrict the summary to include only numerical columns or, if none are, only categorical columns:
In [83]: frame = DataFrame({'a': ['Yes', 'Yes', 'No', 'No'], 'b': range(4)})
In [84]: frame.describe()
Out[84]:
b
count 4.000000
mean 1.500000
std 1.290994
min 0.000000
25% 0.750000
50% 1.500000
75% 2.250000
max 3.000000
This behaviour can be controlled by providing a list of types as include/exclude arguments. The special value all can also be used:
In [85]: frame.describe(include=['object'])
Out[85]:
a
count 4
unique 2
top No
freq 2
In [86]: frame.describe(include=['number'])
Out[86]:
b
count 4.000000
mean 1.500000
std 1.290994
min 0.000000
25% 0.750000
50% 1.500000
75% 2.250000
max 3.000000
In [87]: frame.describe(include='all')
Out[87]:
a b
count 4 4.000000
unique 2 NaN
top No NaN
freq 2 NaN
mean NaN 1.500000
std NaN 1.290994
min NaN 0.000000
25% NaN 0.750000
50% NaN 1.500000
75% NaN 2.250000
max NaN 3.000000
That feature relies on select_dtypes. Refer to there for details about accepted inputs.
Index of Min/Max Values¶
The idxmin() and idxmax() functions on Series and DataFrame compute the index labels with the minimum and maximum corresponding values:
In [88]: s1 = Series(randn(5))
In [89]: s1
Out[89]:
0 -0.872725
1 1.522411
2 0.080594
3 -1.676067
4 0.435804
dtype: float64
In [90]: s1.idxmin(), s1.idxmax()
Out[90]: (3, 1)
In [91]: df1 = DataFrame(randn(5,3), columns=['A','B','C'])
In [92]: df1
Out[92]:
A B C
0 0.445734 -1.649461 0.169660
1 1.246181 0.131682 -2.001988
2 -1.273023 0.870502 0.214583
3 0.088452 -0.173364 1.207466
4 0.546121 0.409515 -0.310515
In [93]: df1.idxmin(axis=0)
Out[93]:
A 2
B 0
C 1
dtype: int64
In [94]: df1.idxmax(axis=1)
Out[94]:
0 A
1 A
2 B
3 C
4 A
dtype: object
When there are multiple rows (or columns) matching the minimum or maximum value, idxmin() and idxmax() return the first matching index:
In [95]: df3 = DataFrame([2, 1, 1, 3, np.nan], columns=['A'], index=list('edcba'))
In [96]: df3
Out[96]:
A
e 2
d 1
c 1
b 3
a NaN
In [97]: df3['A'].idxmin()
Out[97]: 'd'
Note
idxmin and idxmax are called argmin and argmax in NumPy.
Value counts (histogramming) / Mode¶
The value_counts() Series method and top-level function computes a histogram of a 1D array of values. It can also be used as a function on regular arrays:
In [98]: data = np.random.randint(0, 7, size=50)
In [99]: data
Out[99]:
array([5, 3, 2, 2, 1, 4, 0, 4, 0, 2, 0, 6, 4, 1, 6, 3, 3, 0, 2, 1, 0, 5, 5,
3, 6, 1, 5, 6, 2, 0, 0, 6, 3, 3, 5, 0, 4, 3, 3, 3, 0, 6, 1, 3, 5, 5,
0, 4, 0, 6])
In [100]: s = Series(data)
In [101]: s.value_counts()
Out[101]:
0 11
3 10
6 7
5 7
4 5
2 5
1 5
dtype: int64
In [102]: value_counts(data)
Out[102]:
0 11
3 10
6 7
5 7
4 5
2 5
1 5
dtype: int64
Similarly, you can get the most frequently occurring value(s) (the mode) of the values in a Series or DataFrame:
In [103]: s5 = Series([1, 1, 3, 3, 3, 5, 5, 7, 7, 7])
In [104]: s5.mode()
Out[104]:
0 3
1 7
dtype: int64
In [105]: df5 = DataFrame({"A": np.random.randint(0, 7, size=50),
.....: "B": np.random.randint(-10, 15, size=50)})
.....:
In [106]: df5.mode()
Out[106]:
A B
0 1 -5
Discretization and quantiling¶
Continuous values can be discretized using the cut() (bins based on values) and qcut() (bins based on sample quantiles) functions:
In [107]: arr = np.random.randn(20)
In [108]: factor = cut(arr, 4)
In [109]: factor
Out[109]:
[(-0.645, 0.336], (-2.61, -1.626], (-1.626, -0.645], (-1.626, -0.645], (-1.626, -0.645], ..., (0.336, 1.316], (0.336, 1.316], (0.336, 1.316], (0.336, 1.316], (-2.61, -1.626]]
Length: 20
Categories (4, object): [(-2.61, -1.626] < (-1.626, -0.645] < (-0.645, 0.336] < (0.336, 1.316]]
In [110]: factor = cut(arr, [-5, -1, 0, 1, 5])
In [111]: factor
Out[111]:
[(-1, 0], (-5, -1], (-1, 0], (-5, -1], (-1, 0], ..., (0, 1], (1, 5], (0, 1], (0, 1], (-5, -1]]
Length: 20
Categories (4, object): [(-5, -1] < (-1, 0] < (0, 1] < (1, 5]]
qcut() computes sample quantiles. For example, we could slice up some normally distributed data into equal-size quartiles like so:
In [112]: arr = np.random.randn(30)
In [113]: factor = qcut(arr, [0, .25, .5, .75, 1])
In [114]: factor
Out[114]:
[(-0.139, 1.00736], (1.00736, 1.976], (1.00736, 1.976], [-1.0705, -0.439], [-1.0705, -0.439], ..., (1.00736, 1.976], [-1.0705, -0.439], (-0.439, -0.139], (-0.439, -0.139], (-0.439, -0.139]]
Length: 30
Categories (4, object): [[-1.0705, -0.439] < (-0.439, -0.139] < (-0.139, 1.00736] < (1.00736, 1.976]]
In [115]: value_counts(factor)
Out[115]:
(1.00736, 1.976] 8
[-1.0705, -0.439] 8
(-0.139, 1.00736] 7
(-0.439, -0.139] 7
dtype: int64
We can also pass infinite values to define the bins:
In [116]: arr = np.random.randn(20)
In [117]: factor = cut(arr, [-np.inf, 0, np.inf])
In [118]: factor
Out[118]:
[(-inf, 0], (0, inf], (0, inf], (0, inf], (-inf, 0], ..., (-inf, 0], (0, inf], (-inf, 0], (-inf, 0], (0, inf]]
Length: 20
Categories (2, object): [(-inf, 0] < (0, inf]]
Function application¶
Arbitrary functions can be applied along the axes of a DataFrame or Panel using the apply() method, which, like the descriptive statistics methods, take an optional axis argument:
In [119]: df.apply(np.mean)
Out[119]:
one -0.251274
three 0.469799
two -0.191421
dtype: float64
In [120]: df.apply(np.mean, axis=1)
Out[120]:
a -0.489066
b 0.273355
c 0.008348
d 0.011457
dtype: float64
In [121]: df.apply(lambda x: x.max() - x.min())
Out[121]:
one 0.638161
three 1.301762
two 2.237808
dtype: float64
In [122]: df.apply(np.cumsum)
Out[122]:
one three two
a -0.626544 NaN -0.351587
b -0.765438 -0.177289 0.784662
c -0.753821 0.284925 0.335874
d NaN 1.409398 -0.765684
In [123]: df.apply(np.exp)
Out[123]:
one three two
a 0.534436 NaN 0.703570
b 0.870320 0.837537 3.115063
c 1.011685 1.587586 0.638401
d NaN 3.078592 0.332353
Depending on the return type of the function passed to apply(), the result will either be of lower dimension or the same dimension.
apply() combined with some cleverness can be used to answer many questions about a data set. For example, suppose we wanted to extract the date where the maximum value for each column occurred:
In [124]: tsdf = DataFrame(randn(1000, 3), columns=['A', 'B', 'C'],
.....: index=date_range('1/1/2000', periods=1000))
.....:
In [125]: tsdf.apply(lambda x: x.idxmax())
Out[125]:
A 2001-04-27
B 2002-06-02
C 2000-04-02
dtype: datetime64[ns]
You may also pass additional arguments and keyword arguments to the apply() method. For instance, consider the following function you would like to apply:
def subtract_and_divide(x, sub, divide=1):
return (x - sub) / divide
You may then apply this function as follows:
df.apply(subtract_and_divide, args=(5,), divide=3)
Another useful feature is the ability to pass Series methods to carry out some Series operation on each column or row:
In [126]: tsdf
Out[126]:
A B C
2000-01-01 1.796883 -0.930690 3.542846
2000-01-02 -1.242888 -0.695279 -1.000884
2000-01-03 -0.720299 0.546303 -0.082042
2000-01-04 NaN NaN NaN
2000-01-05 NaN NaN NaN
2000-01-06 NaN NaN NaN
2000-01-07 NaN NaN NaN
2000-01-08 -0.527402 0.933507 0.129646
2000-01-09 -0.338903 -1.265452 -1.969004
2000-01-10 0.532566 0.341548 0.150493
In [127]: tsdf.apply(Series.interpolate)
Out[127]:
A B C
2000-01-01 1.796883 -0.930690 3.542846
2000-01-02 -1.242888 -0.695279 -1.000884
2000-01-03 -0.720299 0.546303 -0.082042
2000-01-04 -0.681720 0.623743 -0.039704
2000-01-05 -0.643140 0.701184 0.002633
2000-01-06 -0.604561 0.778625 0.044971
2000-01-07 -0.565982 0.856066 0.087309
2000-01-08 -0.527402 0.933507 0.129646
2000-01-09 -0.338903 -1.265452 -1.969004
2000-01-10 0.532566 0.341548 0.150493
Finally, apply() takes an argument raw which is False by default, which converts each row or column into a Series before applying the function. When set to True, the passed function will instead receive an ndarray object, which has positive performance implications if you do not need the indexing functionality.
See also
The section on GroupBy demonstrates related, flexible functionality for grouping by some criterion, applying, and combining the results into a Series, DataFrame, etc.
Applying elementwise Python functions¶
Since not all functions can be vectorized (accept NumPy arrays and return another array or value), the methods applymap() on DataFrame and analogously map() on Series accept any Python function taking a single value and returning a single value. For example:
In [128]: df4
Out[128]:
one three two
a -0.626544 NaN -0.351587
b -0.138894 -0.177289 1.136249
c 0.011617 0.462215 -0.448789
d NaN 1.124472 -1.101558
In [129]: f = lambda x: len(str(x))
In [130]: df4['one'].map(f)
Out[130]:
a 14
b 15
c 15
d 3
Name: one, dtype: int64
In [131]: df4.applymap(f)
Out[131]:
one three two
a 14 3 15
b 15 15 11
c 15 14 15
d 3 13 14
Series.map() has an additional feature which is that it can be used to easily “link” or “map” values defined by a secondary series. This is closely related to merging/joining functionality:
In [132]: s = Series(['six', 'seven', 'six', 'seven', 'six'],
.....: index=['a', 'b', 'c', 'd', 'e'])
.....:
In [133]: t = Series({'six' : 6., 'seven' : 7.})
In [134]: s
Out[134]:
a six
b seven
c six
d seven
e six
dtype: object
In [135]: s.map(t)
Out[135]:
a 6
b 7
c 6
d 7
e 6
dtype: float64
Applying with a Panel¶
Applying with a Panel will pass a Series to the applied function. If the applied function returns a Series, the result of the application will be a Panel. If the applied function reduces to a scalar, the result of the application will be a DataFrame.
Note
Prior to 0.13.1 apply on a Panel would only work on ufuncs (e.g. np.sum/np.max).
In [136]: import pandas.util.testing as tm
In [137]: panel = tm.makePanel(5)
In [138]: panel
Out[138]:
<class 'pandas.core.panel.Panel'>
Dimensions: 3 (items) x 5 (major_axis) x 4 (minor_axis)
Items axis: ItemA to ItemC
Major_axis axis: 2000-01-03 00:00:00 to 2000-01-07 00:00:00
Minor_axis axis: A to D
In [139]: panel['ItemA']
Out[139]:
A B C D
2000-01-03 0.330418 1.893177 0.801111 0.528154
2000-01-04 1.761200 0.170247 0.445614 -0.029371
2000-01-05 0.567133 -0.916844 1.453046 -0.631117
2000-01-06 -0.251020 0.835024 2.430373 -0.172441
2000-01-07 1.020099 1.259919 0.653093 -1.020485
A transformational apply.
In [140]: result = panel.apply(lambda x: x*2, axis='items')
In [141]: result
Out[141]:
<class 'pandas.core.panel.Panel'>
Dimensions: 3 (items) x 5 (major_axis) x 4 (minor_axis)
Items axis: ItemA to ItemC
Major_axis axis: 2000-01-03 00:00:00 to 2000-01-07 00:00:00
Minor_axis axis: A to D
In [142]: result['ItemA']
Out[142]:
A B C D
2000-01-03 0.660836 3.786354 1.602222 1.056308
2000-01-04 3.522400 0.340494 0.891228 -0.058742
2000-01-05 1.134266 -1.833689 2.906092 -1.262234
2000-01-06 -0.502039 1.670047 4.860747 -0.344882
2000-01-07 2.040199 2.519838 1.306185 -2.040969
A reduction operation.
In [143]: panel.apply(lambda x: x.dtype, axis='items')
Out[143]:
A B C D
2000-01-03 float64 float64 float64 float64
2000-01-04 float64 float64 float64 float64
2000-01-05 float64 float64 float64 float64
2000-01-06 float64 float64 float64 float64
2000-01-07 float64 float64 float64 float64
A similar reduction type operation
In [144]: panel.apply(lambda x: x.sum(), axis='major_axis')
Out[144]:
ItemA ItemB ItemC
A 3.427831 -2.581431 0.840809
B 3.241522 -1.409935 -1.114512
C 5.783237 0.319672 -0.431906
D -1.325260 -2.914834 0.857043
This last reduction is equivalent to
In [145]: panel.sum('major_axis')
Out[145]:
ItemA ItemB ItemC
A 3.427831 -2.581431 0.840809
B 3.241522 -1.409935 -1.114512
C 5.783237 0.319672 -0.431906
D -1.325260 -2.914834 0.857043
A transformation operation that returns a Panel, but is computing the z-score across the major_axis.
In [146]: result = panel.apply(
.....: lambda x: (x-x.mean())/x.std(),
.....: axis='major_axis')
.....:
In [147]: result
Out[147]:
<class 'pandas.core.panel.Panel'>
Dimensions: 3 (items) x 5 (major_axis) x 4 (minor_axis)
Items axis: ItemA to ItemC
Major_axis axis: 2000-01-03 00:00:00 to 2000-01-07 00:00:00
Minor_axis axis: A to D
In [148]: result['ItemA']
Out[148]:
A B C D
2000-01-03 -0.469761 1.156225 -0.441347 1.341731
2000-01-04 1.422763 -0.444015 -0.882647 0.398661
2000-01-05 -0.156654 -1.453694 0.367936 -0.619210
2000-01-06 -1.238841 0.173423 1.581149 0.156654
2000-01-07 0.442494 0.568061 -0.625091 -1.277837
Apply can also accept multiple axes in the axis argument. This will pass a DataFrame of the cross-section to the applied function.
In [149]: f = lambda x: ((x.T-x.mean(1))/x.std(1)).T
In [150]: result = panel.apply(f, axis = ['items','major_axis'])
In [151]: result
Out[151]:
<class 'pandas.core.panel.Panel'>
Dimensions: 4 (items) x 5 (major_axis) x 3 (minor_axis)
Items axis: A to D
Major_axis axis: 2000-01-03 00:00:00 to 2000-01-07 00:00:00
Minor_axis axis: ItemA to ItemC
In [152]: result.loc[:,:,'ItemA']
Out[152]:
A B C D
2000-01-03 0.864236 1.132969 0.557316 0.575106
2000-01-04 0.795745 0.652527 0.534808 -0.070674
2000-01-05 -0.310864 0.558627 1.086688 -1.051477
2000-01-06 -0.001065 0.832460 0.846006 0.043602
2000-01-07 1.128946 1.152469 -0.218186 -0.891680
This is equivalent to the following
In [153]: result = Panel(dict([ (ax,f(panel.loc[:,:,ax]))
.....: for ax in panel.minor_axis ]))
.....:
In [154]: result
Out[154]:
<class 'pandas.core.panel.Panel'>
Dimensions: 4 (items) x 5 (major_axis) x 3 (minor_axis)
Items axis: A to D
Major_axis axis: 2000-01-03 00:00:00 to 2000-01-07 00:00:00
Minor_axis axis: ItemA to ItemC
In [155]: result.loc[:,:,'ItemA']
Out[155]:
A B C D
2000-01-03 0.864236 1.132969 0.557316 0.575106
2000-01-04 0.795745 0.652527 0.534808 -0.070674
2000-01-05 -0.310864 0.558627 1.086688 -1.051477
2000-01-06 -0.001065 0.832460 0.846006 0.043602
2000-01-07 1.128946 1.152469 -0.218186 -0.891680
Reindexing and altering labels¶
reindex() is the fundamental data alignment method in pandas. It is used to implement nearly all other features relying on label-alignment functionality. To reindex means to conform the data to match a given set of labels along a particular axis. This accomplishes several things:
- Reorders the existing data to match a new set of labels
- Inserts missing value (NA) markers in label locations where no data for that label existed
- If specified, fill data for missing labels using logic (highly relevant to working with time series data)
Here is a simple example:
In [156]: s = Series(randn(5), index=['a', 'b', 'c', 'd', 'e'])
In [157]: s
Out[157]:
a -1.010924
b -0.672504
c -1.139222
d 0.354653
e 0.563622
dtype: float64
In [158]: s.reindex(['e', 'b', 'f', 'd'])
Out[158]:
e 0.563622
b -0.672504
f NaN
d 0.354653
dtype: float64
Here, the f label was not contained in the Series and hence appears as NaN in the result.
With a DataFrame, you can simultaneously reindex the index and columns:
In [159]: df
Out[159]:
one three two
a -0.626544 NaN -0.351587
b -0.138894 -0.177289 1.136249
c 0.011617 0.462215 -0.448789
d NaN 1.124472 -1.101558
In [160]: df.reindex(index=['c', 'f', 'b'], columns=['three', 'two', 'one'])
Out[160]:
three two one
c 0.462215 -0.448789 0.011617
f NaN NaN NaN
b -0.177289 1.136249 -0.138894
For convenience, you may utilize the reindex_axis() method, which takes the labels and a keyword axis parameter.
Note that the Index objects containing the actual axis labels can be shared between objects. So if we have a Series and a DataFrame, the following can be done:
In [161]: rs = s.reindex(df.index)
In [162]: rs
Out[162]:
a -1.010924
b -0.672504
c -1.139222
d 0.354653
dtype: float64
In [163]: rs.index is df.index
Out[163]: True
This means that the reindexed Series’s index is the same Python object as the DataFrame’s index.
See also
MultiIndex / Advanced Indexing is an even more concise way of doing reindexing.
Note
When writing performance-sensitive code, there is a good reason to spend some time becoming a reindexing ninja: many operations are faster on pre-aligned data. Adding two unaligned DataFrames internally triggers a reindexing step. For exploratory analysis you will hardly notice the difference (because reindex has been heavily optimized), but when CPU cycles matter sprinkling a few explicit reindex calls here and there can have an impact.
Reindexing to align with another object¶
You may wish to take an object and reindex its axes to be labeled the same as another object. While the syntax for this is straightforward albeit verbose, it is a common enough operation that the reindex_like() method is available to make this simpler:
In [164]: df2
Out[164]:
one two
a -0.626544 -0.351587
b -0.138894 1.136249
c 0.011617 -0.448789
In [165]: df3
Out[165]:
one two
a -0.375270 -0.463545
b 0.112379 1.024292
c 0.262891 -0.560746
In [166]: df.reindex_like(df2)
Out[166]:
one two
a -0.626544 -0.351587
b -0.138894 1.136249
c 0.011617 -0.448789
Aligning objects with each other with align¶
The align() method is the fastest way to simultaneously align two objects. It supports a join argument (related to joining and merging):
- join='outer': take the union of the indexes (default)
- join='left': use the calling object’s index
- join='right': use the passed object’s index
- join='inner': intersect the indexes
It returns a tuple with both of the reindexed Series:
In [167]: s = Series(randn(5), index=['a', 'b', 'c', 'd', 'e'])
In [168]: s1 = s[:4]
In [169]: s2 = s[1:]
In [170]: s1.align(s2)
Out[170]:
(a -0.365106
b 1.092702
c -1.481449
d 1.781190
e NaN
dtype: float64, a NaN
b 1.092702
c -1.481449
d 1.781190
e -0.031543
dtype: float64)
In [171]: s1.align(s2, join='inner')
Out[171]:
(b 1.092702
c -1.481449
d 1.781190
dtype: float64, b 1.092702
c -1.481449
d 1.781190
dtype: float64)
In [172]: s1.align(s2, join='left')
Out[172]:
(a -0.365106
b 1.092702
c -1.481449
d 1.781190
dtype: float64, a NaN
b 1.092702
c -1.481449
d 1.781190
dtype: float64)
For DataFrames, the join method will be applied to both the index and the columns by default:
In [173]: df.align(df2, join='inner')
Out[173]:
( one two
a -0.626544 -0.351587
b -0.138894 1.136249
c 0.011617 -0.448789, one two
a -0.626544 -0.351587
b -0.138894 1.136249
c 0.011617 -0.448789)
You can also pass an axis option to only align on the specified axis:
In [174]: df.align(df2, join='inner', axis=0)
Out[174]:
( one three two
a -0.626544 NaN -0.351587
b -0.138894 -0.177289 1.136249
c 0.011617 0.462215 -0.448789, one two
a -0.626544 -0.351587
b -0.138894 1.136249
c 0.011617 -0.448789)
If you pass a Series to DataFrame.align(), you can choose to align both objects either on the DataFrame’s index or columns using the axis argument:
In [175]: df.align(df2.ix[0], axis=1)
Out[175]:
( one three two
a -0.626544 NaN -0.351587
b -0.138894 -0.177289 1.136249
c 0.011617 0.462215 -0.448789
d NaN 1.124472 -1.101558, one -0.626544
three NaN
two -0.351587
Name: a, dtype: float64)
Filling while reindexing¶
reindex() takes an optional parameter method which is a filling method chosen from the following table:
| Method | Action |
|---|---|
| pad / ffill | Fill values forward |
| bfill / backfill | Fill values backward |
| nearest | Fill from the nearest index value |
We illustrate these fill methods on a simple Series:
In [176]: rng = date_range('1/3/2000', periods=8)
In [177]: ts = Series(randn(8), index=rng)
In [178]: ts2 = ts[[0, 3, 6]]
In [179]: ts
Out[179]:
2000-01-03 0.480993
2000-01-04 0.604244
2000-01-05 -0.487265
2000-01-06 1.990533
2000-01-07 0.327007
2000-01-08 1.053639
2000-01-09 -2.927808
2000-01-10 0.082065
Freq: D, dtype: float64
In [180]: ts2
Out[180]:
2000-01-03 0.480993
2000-01-06 1.990533
2000-01-09 -2.927808
dtype: float64
In [181]: ts2.reindex(ts.index)
Out[181]:
2000-01-03 0.480993
2000-01-04 NaN
2000-01-05 NaN
2000-01-06 1.990533
2000-01-07 NaN
2000-01-08 NaN
2000-01-09 -2.927808
2000-01-10 NaN
Freq: D, dtype: float64
In [182]: ts2.reindex(ts.index, method='ffill')
Out[182]:
2000-01-03 0.480993
2000-01-04 0.480993
2000-01-05 0.480993
2000-01-06 1.990533
2000-01-07 1.990533
2000-01-08 1.990533
2000-01-09 -2.927808
2000-01-10 -2.927808
Freq: D, dtype: float64
In [183]: ts2.reindex(ts.index, method='bfill')
Out[183]:
2000-01-03 0.480993
2000-01-04 1.990533
2000-01-05 1.990533
2000-01-06 1.990533
2000-01-07 -2.927808
2000-01-08 -2.927808
2000-01-09 -2.927808
2000-01-10 NaN
Freq: D, dtype: float64
In [184]: ts2.reindex(ts.index, method='nearest')
Out[184]:
2000-01-03 0.480993
2000-01-04 0.480993
2000-01-05 1.990533
2000-01-06 1.990533
2000-01-07 1.990533
2000-01-08 -2.927808
2000-01-09 -2.927808
2000-01-10 -2.927808
Freq: D, dtype: float64
These methods require that the indexes are ordered increasing or decreasing.
Note that the same result could have been achieved using fillna (except for method='nearest') or interpolate:
In [185]: ts2.reindex(ts.index).fillna(method='ffill')
Out[185]:
2000-01-03 0.480993
2000-01-04 0.480993
2000-01-05 0.480993
2000-01-06 1.990533
2000-01-07 1.990533
2000-01-08 1.990533
2000-01-09 -2.927808
2000-01-10 -2.927808
Freq: D, dtype: float64
reindex() will raise a ValueError if the index is not monotonic increasing or descreasing. fillna() and interpolate() will not make any checks on the order of the index.
Dropping labels from an axis¶
A method closely related to reindex is the drop() function. It removes a set of labels from an axis:
In [186]: df
Out[186]:
one three two
a -0.626544 NaN -0.351587
b -0.138894 -0.177289 1.136249
c 0.011617 0.462215 -0.448789
d NaN 1.124472 -1.101558
In [187]: df.drop(['a', 'd'], axis=0)
Out[187]:
one three two
b -0.138894 -0.177289 1.136249
c 0.011617 0.462215 -0.448789
In [188]: df.drop(['one'], axis=1)
Out[188]:
three two
a NaN -0.351587
b -0.177289 1.136249
c 0.462215 -0.448789
d 1.124472 -1.101558
Note that the following also works, but is a bit less obvious / clean:
In [189]: df.reindex(df.index.difference(['a', 'd']))
Out[189]:
one three two
b -0.138894 -0.177289 1.136249
c 0.011617 0.462215 -0.448789
Renaming / mapping labels¶
The rename() method allows you to relabel an axis based on some mapping (a dict or Series) or an arbitrary function.
In [190]: s
Out[190]:
a -0.365106
b 1.092702
c -1.481449
d 1.781190
e -0.031543
dtype: float64
In [191]: s.rename(str.upper)
Out[191]:
A -0.365106
B 1.092702
C -1.481449
D 1.781190
E -0.031543
dtype: float64
If you pass a function, it must return a value when called with any of the labels (and must produce a set of unique values). But if you pass a dict or Series, it need only contain a subset of the labels as keys:
In [192]: df.rename(columns={'one' : 'foo', 'two' : 'bar'},
.....: index={'a' : 'apple', 'b' : 'banana', 'd' : 'durian'})
.....:
Out[192]:
foo three bar
apple -0.626544 NaN -0.351587
banana -0.138894 -0.177289 1.136249
c 0.011617 0.462215 -0.448789
durian NaN 1.124472 -1.101558
The rename() method also provides an inplace named parameter that is by default False and copies the underlying data. Pass inplace=True to rename the data in place.
The Panel class has a related rename_axis() class which can rename any of its three axes.
Iteration¶
Because Series is array-like, basic iteration produces the values. Other data structures follow the dict-like convention of iterating over the “keys” of the objects. In short:
- Series: values
- DataFrame: column labels
- Panel: item labels
Thus, for example:
In [193]: for col in df:
.....: print(col)
.....:
one
three
two
iteritems¶
Consistent with the dict-like interface, iteritems() iterates through key-value pairs:
- Series: (index, scalar value) pairs
- DataFrame: (column, Series) pairs
- Panel: (item, DataFrame) pairs
For example:
In [194]: for item, frame in wp.iteritems():
.....: print(item)
.....: print(frame)
.....:
Item1
A B C D
2000-01-01 -1.032011 0.969818 -0.962723 1.382083
2000-01-02 -0.938794 0.669142 -0.433567 -0.273610
2000-01-03 0.680433 -0.308450 -0.276099 -1.821168
2000-01-04 -1.993606 -1.927385 -2.027924 1.624972
2000-01-05 0.551135 3.059267 0.455264 -0.030740
Item2
A B C D
2000-01-01 0.935716 1.061192 -2.107852 0.199905
2000-01-02 0.323586 -0.641630 -0.587514 0.053897
2000-01-03 0.194889 -0.381994 0.318587 2.089075
2000-01-04 -0.728293 -0.090255 -0.748199 1.318931
2000-01-05 -2.029766 0.792652 0.461007 -0.542749
iterrows¶
New in v0.7 is the ability to iterate efficiently through rows of a DataFrame with iterrows(). It returns an iterator yielding each index value along with a Series containing the data in each row:
In [195]: for row_index, row in df2.iterrows():
.....: print('%s\n%s' % (row_index, row))
.....:
a
one -0.626544
two -0.351587
Name: a, dtype: float64
b
one -0.138894
two 1.136249
Name: b, dtype: float64
c
one 0.011617
two -0.448789
Name: c, dtype: float64
For instance, a contrived way to transpose the DataFrame would be:
In [196]: df2 = DataFrame({'x': [1, 2, 3], 'y': [4, 5, 6]})
In [197]: print(df2)
x y
0 1 4
1 2 5
2 3 6
In [198]: print(df2.T)
0 1 2
x 1 2 3
y 4 5 6
In [199]: df2_t = DataFrame(dict((idx,values) for idx, values in df2.iterrows()))
In [200]: print(df2_t)
0 1 2
x 1 2 3
y 4 5 6
Note
iterrows does not preserve dtypes across the rows (dtypes are preserved across columns for DataFrames). For example,
In [201]: df_iter = DataFrame([[1, 1.0]], columns=['x', 'y']) In [202]: row = next(df_iter.iterrows())[1] In [203]: print(row['x'].dtype) float64 In [204]: print(df_iter['x'].dtype) int64
itertuples¶
The itertuples() method will return an iterator yielding a tuple for each row in the DataFrame. The first element of the tuple will be the row’s corresponding index value, while the remaining values are the row values proper.
For instance,
In [205]: for r in df2.itertuples():
.....: print(r)
.....:
(0, 1, 4)
(1, 2, 5)
(2, 3, 6)
.dt accessor¶
Series has an accessor to succinctly return datetime like properties for the values of the Series, if its a datetime/period like Series. This will return a Series, indexed like the existing Series.
# datetime
In [206]: s = Series(date_range('20130101 09:10:12',periods=4))
In [207]: s
Out[207]:
0 2013-01-01 09:10:12
1 2013-01-02 09:10:12
2 2013-01-03 09:10:12
3 2013-01-04 09:10:12
dtype: datetime64[ns]
In [208]: s.dt.hour
Out[208]:
0 9
1 9
2 9
3 9
dtype: int64
In [209]: s.dt.second
Out[209]:
0 12
1 12
2 12
3 12
dtype: int64
In [210]: s.dt.day
Out[210]:
0 1
1 2
2 3
3 4
dtype: int64
This enables nice expressions like this:
In [211]: s[s.dt.day==2]
Out[211]:
1 2013-01-02 09:10:12
dtype: datetime64[ns]
You can easily produces tz aware transformations:
In [212]: stz = s.dt.tz_localize('US/Eastern')
In [213]: stz
Out[213]:
0 2013-01-01 09:10:12-05:00
1 2013-01-02 09:10:12-05:00
2 2013-01-03 09:10:12-05:00
3 2013-01-04 09:10:12-05:00
dtype: object
In [214]: stz.dt.tz
Out[214]: <DstTzInfo 'US/Eastern' LMT-1 day, 19:04:00 STD>
You can also chain these types of operations:
In [215]: s.dt.tz_localize('UTC').dt.tz_convert('US/Eastern')
Out[215]:
0 2013-01-01 04:10:12-05:00
1 2013-01-02 04:10:12-05:00
2 2013-01-03 04:10:12-05:00
3 2013-01-04 04:10:12-05:00
dtype: object
The .dt accessor works for period and timedelta dtypes.
# period
In [216]: s = Series(period_range('20130101',periods=4,freq='D'))
In [217]: s
Out[217]:
0 2013-01-01
1 2013-01-02
2 2013-01-03
3 2013-01-04
dtype: object
In [218]: s.dt.year
Out[218]:
0 2013
1 2013
2 2013
3 2013
dtype: int64
In [219]: s.dt.day
Out[219]:
0 1
1 2
2 3
3 4
dtype: int64
# timedelta
In [220]: s = Series(timedelta_range('1 day 00:00:05',periods=4,freq='s'))
In [221]: s
Out[221]:
0 1 days 00:00:05
1 1 days 00:00:06
2 1 days 00:00:07
3 1 days 00:00:08
dtype: timedelta64[ns]
In [222]: s.dt.days
Out[222]:
0 1
1 1
2 1
3 1
dtype: int64
In [223]: s.dt.seconds
Out[223]:
0 5
1 6
2 7
3 8
dtype: int64
In [224]: s.dt.components
Out[224]:
days hours minutes seconds milliseconds microseconds nanoseconds
0 1 0 0 5 0 0 0
1 1 0 0 6 0 0 0
2 1 0 0 7 0 0 0
3 1 0 0 8 0 0 0
Note
Series.dt will raise a TypeError if you access with a non-datetimelike values
Vectorized string methods¶
Series is equipped with a set of string processing methods that make it easy to operate on each element of the array. Perhaps most importantly, these methods exclude missing/NA values automatically. These are accessed via the Series’s str attribute and generally have names matching the equivalent (scalar) built-in string methods. For example:
In [225]: s = Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat']) In [226]: s.str.lower() Out[226]: 0 a 1 b 2 c 3 aaba 4 baca 5 NaN 6 caba 7 dog 8 cat dtype: object
Powerful pattern-matching methods are provided as well, but note that pattern-matching generally uses regular expressions by default (and in some cases always uses them).
Please see Vectorized String Methods for a complete description.
Sorting by index and value¶
There are two obvious kinds of sorting that you may be interested in: sorting by label and sorting by actual values. The primary method for sorting axis labels (indexes) across data structures is the sort_index() method.
In [227]: unsorted_df = df.reindex(index=['a', 'd', 'c', 'b'],
.....: columns=['three', 'two', 'one'])
.....:
In [228]: unsorted_df.sort_index()
Out[228]:
three two one
a NaN -0.351587 -0.626544
b -0.177289 1.136249 -0.138894
c 0.462215 -0.448789 0.011617
d 1.124472 -1.101558 NaN
In [229]: unsorted_df.sort_index(ascending=False)
Out[229]:
three two one
d 1.124472 -1.101558 NaN
c 0.462215 -0.448789 0.011617
b -0.177289 1.136249 -0.138894
a NaN -0.351587 -0.626544
In [230]: unsorted_df.sort_index(axis=1)
Out[230]:
one three two
a -0.626544 NaN -0.351587
d NaN 1.124472 -1.101558
c 0.011617 0.462215 -0.448789
b -0.138894 -0.177289 1.136249
DataFrame.sort_index() can accept an optional by argument for axis=0 which will use an arbitrary vector or a column name of the DataFrame to determine the sort order:
In [231]: df1 = DataFrame({'one':[2,1,1,1],'two':[1,3,2,4],'three':[5,4,3,2]})
In [232]: df1.sort_index(by='two')
Out[232]:
one three two
0 2 5 1
2 1 3 2
1 1 4 3
3 1 2 4
The by argument can take a list of column names, e.g.:
In [233]: df1[['one', 'two', 'three']].sort_index(by=['one','two'])
Out[233]:
one two three
2 1 2 3
1 1 3 4
3 1 4 2
0 2 1 5
Series has the method order() (analogous to R’s order function) which sorts by value, with special treatment of NA values via the na_position argument:
In [234]: s[2] = np.nan
In [235]: s.order()
Out[235]:
0 A
3 Aaba
1 B
4 Baca
6 CABA
8 cat
7 dog
2 NaN
5 NaN
dtype: object
In [236]: s.order(na_position='first')
Out[236]:
2 NaN
5 NaN
0 A
3 Aaba
1 B
4 Baca
6 CABA
8 cat
7 dog
dtype: object
Note
Series.sort() sorts a Series by value in-place. This is to provide compatibility with NumPy methods which expect the ndarray.sort behavior. Series.order() returns a copy of the sorted data.
Series has the searchsorted() method, which works similar to numpy.ndarray.searchsorted().
In [237]: ser = Series([1, 2, 3])
In [238]: ser.searchsorted([0, 3])
Out[238]: array([0, 2])
In [239]: ser.searchsorted([0, 4])
Out[239]: array([0, 3])
In [240]: ser.searchsorted([1, 3], side='right')
Out[240]: array([1, 3])
In [241]: ser.searchsorted([1, 3], side='left')
Out[241]: array([0, 2])
In [242]: ser = Series([3, 1, 2])
In [243]: ser.searchsorted([0, 3], sorter=np.argsort(ser))
Out[243]: array([0, 2])
smallest / largest values¶
New in version 0.14.0.
Series has the nsmallest() and nlargest() methods which return the
smallest or largest 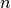 values. For a large Series this can be much
faster than sorting the entire Series and calling head(n) on the result.
values. For a large Series this can be much
faster than sorting the entire Series and calling head(n) on the result.
In [244]: s = Series(np.random.permutation(10))
In [245]: s
Out[245]:
0 7
1 5
2 4
3 6
4 1
5 8
6 9
7 2
8 0
9 3
dtype: int32
In [246]: s.order()
Out[246]:
8 0
4 1
7 2
9 3
2 4
1 5
3 6
0 7
5 8
6 9
dtype: int32
In [247]: s.nsmallest(3)
Out[247]:
8 0
4 1
7 2
dtype: int32
In [248]: s.nlargest(3)
Out[248]:
6 9
5 8
0 7
dtype: int32
Sorting by a multi-index column¶
You must be explicit about sorting when the column is a multi-index, and fully specify all levels to by.
In [249]: df1.columns = MultiIndex.from_tuples([('a','one'),('a','two'),('b','three')])
In [250]: df1.sort_index(by=('a','two'))
Out[250]:
a b
one two three
3 1 2 4
2 1 3 2
1 1 4 3
0 2 5 1
Copying¶
The copy() method on pandas objects copies the underlying data (though not the axis indexes, since they are immutable) and returns a new object. Note that it is seldom necessary to copy objects. For example, there are only a handful of ways to alter a DataFrame in-place:
- Inserting, deleting, or modifying a column
- Assigning to the index or columns attributes
- For homogeneous data, directly modifying the values via the values attribute or advanced indexing
To be clear, no pandas methods have the side effect of modifying your data; almost all methods return new objects, leaving the original object untouched. If data is modified, it is because you did so explicitly.
dtypes¶
The main types stored in pandas objects are float, int, bool, datetime64[ns], timedelta[ns] and object. In addition these dtypes have item sizes, e.g. int64 and int32. A convenient dtypes` attribute for DataFrames returns a Series with the data type of each column.
In [251]: dft = DataFrame(dict( A = np.random.rand(3),
.....: B = 1,
.....: C = 'foo',
.....: D = Timestamp('20010102'),
.....: E = Series([1.0]*3).astype('float32'),
.....: F = False,
.....: G = Series([1]*3,dtype='int8')))
.....:
In [252]: dft
Out[252]:
A B C D E F G
0 0.028931 1 foo 2001-01-02 1 False 1
1 0.936706 1 foo 2001-01-02 1 False 1
2 0.831782 1 foo 2001-01-02 1 False 1
In [253]: dft.dtypes
Out[253]:
A float64
B int64
C object
D datetime64[ns]
E float32
F bool
G int8
dtype: object
On a Series use the dtype attribute.
In [254]: dft['A'].dtype
Out[254]: dtype('float64')
If a pandas object contains data multiple dtypes IN A SINGLE COLUMN, the dtype of the column will be chosen to accommodate all of the data types (object is the most general).
# these ints are coerced to floats
In [255]: Series([1, 2, 3, 4, 5, 6.])
Out[255]:
0 1
1 2
2 3
3 4
4 5
5 6
dtype: float64
# string data forces an ``object`` dtype
In [256]: Series([1, 2, 3, 6., 'foo'])
Out[256]:
0 1
1 2
2 3
3 6
4 foo
dtype: object
The method get_dtype_counts() will return the number of columns of each type in a DataFrame:
In [257]: dft.get_dtype_counts()
Out[257]:
bool 1
datetime64[ns] 1
float32 1
float64 1
int64 1
int8 1
object 1
dtype: int64
Numeric dtypes will propagate and can coexist in DataFrames (starting in v0.11.0). If a dtype is passed (either directly via the dtype keyword, a passed ndarray, or a passed Series, then it will be preserved in DataFrame operations. Furthermore, different numeric dtypes will NOT be combined. The following example will give you a taste.
In [258]: df1 = DataFrame(randn(8, 1), columns = ['A'], dtype = 'float32')
In [259]: df1
Out[259]:
A
0 1.213978
1 -0.505425
2 0.254678
3 -0.744834
4 0.647650
5 0.822993
6 1.778703
7 -1.543048
In [260]: df1.dtypes
Out[260]:
A float32
dtype: object
In [261]: df2 = DataFrame(dict( A = Series(randn(8),dtype='float16'),
.....: B = Series(randn(8)),
.....: C = Series(np.array(randn(8),dtype='uint8')) ))
.....:
In [262]: df2
Out[262]:
A B C
0 -0.123230 -1.508174 0
1 2.240234 -0.502623 0
2 -0.143799 0.529008 0
3 -2.884766 0.590536 1
4 0.027588 0.296947 0
5 -1.150391 0.007045 255
6 0.246460 0.707877 1
7 -0.455078 0.950661 0
In [263]: df2.dtypes
Out[263]:
A float16
B float64
C uint8
dtype: object
defaults¶
By default integer types are int64 and float types are float64, REGARDLESS of platform (32-bit or 64-bit). The following will all result in int64 dtypes.
In [264]: DataFrame([1, 2], columns=['a']).dtypes
Out[264]:
a int64
dtype: object
In [265]: DataFrame({'a': [1, 2]}).dtypes
Out[265]:
a int64
dtype: object
In [266]: DataFrame({'a': 1 }, index=list(range(2))).dtypes
Out[266]:
a int64
dtype: object
Numpy, however will choose platform-dependent types when creating arrays. The following WILL result in int32 on 32-bit platform.
In [267]: frame = DataFrame(np.array([1, 2]))
upcasting¶
Types can potentially be upcasted when combined with other types, meaning they are promoted from the current type (say int to float)
In [268]: df3 = df1.reindex_like(df2).fillna(value=0.0) + df2
In [269]: df3
Out[269]:
A B C
0 1.090748 -1.508174 0
1 1.734810 -0.502623 0
2 0.110879 0.529008 0
3 -3.629600 0.590536 1
4 0.675238 0.296947 0
5 -0.327398 0.007045 255
6 2.025163 0.707877 1
7 -1.998126 0.950661 0
In [270]: df3.dtypes
Out[270]:
A float32
B float64
C float64
dtype: object
The values attribute on a DataFrame return the lower-common-denominator of the dtypes, meaning the dtype that can accommodate ALL of the types in the resulting homogeneous dtyped numpy array. This can force some upcasting.
In [271]: df3.values.dtype
Out[271]: dtype('float64')
astype¶
You can use the astype() method to explicitly convert dtypes from one to another. These will by default return a copy, even if the dtype was unchanged (pass copy=False to change this behavior). In addition, they will raise an exception if the astype operation is invalid.
Upcasting is always according to the numpy rules. If two different dtypes are involved in an operation, then the more general one will be used as the result of the operation.
In [272]: df3
Out[272]:
A B C
0 1.090748 -1.508174 0
1 1.734810 -0.502623 0
2 0.110879 0.529008 0
3 -3.629600 0.590536 1
4 0.675238 0.296947 0
5 -0.327398 0.007045 255
6 2.025163 0.707877 1
7 -1.998126 0.950661 0
In [273]: df3.dtypes
Out[273]:
A float32
B float64
C float64
dtype: object
# conversion of dtypes
In [274]: df3.astype('float32').dtypes
Out[274]:
A float32
B float32
C float32
dtype: object
object conversion¶
convert_objects() is a method to try to force conversion of types from the object dtype to other types. To force conversion of specific types that are number like, e.g. could be a string that represents a number, pass convert_numeric=True. This will force strings and numbers alike to be numbers if possible, otherwise they will be set to np.nan.
In [275]: df3['D'] = '1.'
In [276]: df3['E'] = '1'
In [277]: df3.convert_objects(convert_numeric=True).dtypes
Out[277]:
A float32
B float64
C float64
D float64
E int64
dtype: object
# same, but specific dtype conversion
In [278]: df3['D'] = df3['D'].astype('float16')
In [279]: df3['E'] = df3['E'].astype('int32')
In [280]: df3.dtypes
Out[280]:
A float32
B float64
C float64
D float16
E int32
dtype: object
To force conversion to datetime64[ns], pass convert_dates='coerce'. This will convert any datetime-like object to dates, forcing other values to NaT. This might be useful if you are reading in data which is mostly dates, but occasionally has non-dates intermixed and you want to represent as missing.
In [281]: s = Series([datetime(2001,1,1,0,0),
.....: 'foo', 1.0, 1, Timestamp('20010104'),
.....: '20010105'],dtype='O')
.....:
In [282]: s
Out[282]:
0 2001-01-01 00:00:00
1 foo
2 1
3 1
4 2001-01-04 00:00:00
5 20010105
dtype: object
In [283]: s.convert_objects(convert_dates='coerce')
Out[283]:
0 2001-01-01
1 NaT
2 NaT
3 NaT
4 2001-01-04
5 2001-01-05
dtype: datetime64[ns]
In addition, convert_objects() will attempt the soft conversion of any object dtypes, meaning that if all the objects in a Series are of the same type, the Series will have that dtype.
gotchas¶
Performing selection operations on integer type data can easily upcast the data to floating. The dtype of the input data will be preserved in cases where nans are not introduced (starting in 0.11.0) See also integer na gotchas
In [284]: dfi = df3.astype('int32')
In [285]: dfi['E'] = 1
In [286]: dfi
Out[286]:
A B C D E
0 1 -1 0 1 1
1 1 0 0 1 1
2 0 0 0 1 1
3 -3 0 1 1 1
4 0 0 0 1 1
5 0 0 255 1 1
6 2 0 1 1 1
7 -1 0 0 1 1
In [287]: dfi.dtypes
Out[287]:
A int32
B int32
C int32
D int32
E int64
dtype: object
In [288]: casted = dfi[dfi>0]
In [289]: casted
Out[289]:
A B C D E
0 1 NaN NaN 1 1
1 1 NaN NaN 1 1
2 NaN NaN NaN 1 1
3 NaN NaN 1 1 1
4 NaN NaN NaN 1 1
5 NaN NaN 255 1 1
6 2 NaN 1 1 1
7 NaN NaN NaN 1 1
In [290]: casted.dtypes
Out[290]:
A float64
B float64
C float64
D int32
E int64
dtype: object
While float dtypes are unchanged.
In [291]: dfa = df3.copy()
In [292]: dfa['A'] = dfa['A'].astype('float32')
In [293]: dfa.dtypes
Out[293]:
A float32
B float64
C float64
D float16
E int32
dtype: object
In [294]: casted = dfa[df2>0]
In [295]: casted
Out[295]:
A B C D E
0 NaN NaN NaN NaN NaN
1 1.734810 NaN NaN NaN NaN
2 NaN 0.529008 NaN NaN NaN
3 NaN 0.590536 1 NaN NaN
4 0.675238 0.296947 NaN NaN NaN
5 NaN 0.007045 255 NaN NaN
6 2.025163 0.707877 1 NaN NaN
7 NaN 0.950661 NaN NaN NaN
In [296]: casted.dtypes
Out[296]:
A float32
B float64
C float64
D float16
E float64
dtype: object
Selecting columns based on dtype¶
New in version 0.14.1.
The select_dtypes() method implements subsetting of columns based on their dtype.
First, let’s create a DataFrame with a slew of different dtypes:
In [297]: df = DataFrame({'string': list('abc'),
.....: 'int64': list(range(1, 4)),
.....: 'uint8': np.arange(3, 6).astype('u1'),
.....: 'float64': np.arange(4.0, 7.0),
.....: 'bool1': [True, False, True],
.....: 'bool2': [False, True, False],
.....: 'dates': pd.date_range('now', periods=3).values,
.....: 'category': pd.Categorical(list("ABC"))})
.....:
In [298]: df['tdeltas'] = df.dates.diff()
In [299]: df['uint64'] = np.arange(3, 6).astype('u8')
In [300]: df['other_dates'] = pd.date_range('20130101', periods=3).values
In [301]: df
Out[301]:
bool1 bool2 category dates float64 int64 string \
0 True False A 2015-05-11 11:00:20.785134 4 1 a
1 False True B 2015-05-12 11:00:20.785134 5 2 b
2 True False C 2015-05-13 11:00:20.785134 6 3 c
uint8 tdeltas uint64 other_dates
0 3 NaT 3 2013-01-01
1 4 1 days 4 2013-01-02
2 5 1 days 5 2013-01-03
select_dtypes() has two parameters include and exclude that allow you to say “give me the columns WITH these dtypes” (include) and/or “give the columns WITHOUT these dtypes” (exclude).
For example, to select bool columns
In [302]: df.select_dtypes(include=[bool])
Out[302]:
bool1 bool2
0 True False
1 False True
2 True False
You can also pass the name of a dtype in the numpy dtype hierarchy:
In [303]: df.select_dtypes(include=['bool'])
Out[303]:
bool1 bool2
0 True False
1 False True
2 True False
select_dtypes() also works with generic dtypes as well.
For example, to select all numeric and boolean columns while excluding unsigned integers
In [304]: df.select_dtypes(include=['number', 'bool'], exclude=['unsignedinteger'])
Out[304]:
bool1 bool2 float64 int64 tdeltas
0 True False 4 1 NaT
1 False True 5 2 1 days
2 True False 6 3 1 days
To select string columns you must use the object dtype:
In [305]: df.select_dtypes(include=['object'])
Out[305]:
string
0 a
1 b
2 c
To see all the child dtypes of a generic dtype like numpy.number you can define a function that returns a tree of child dtypes:
In [306]: def subdtypes(dtype):
.....: subs = dtype.__subclasses__()
.....: if not subs:
.....: return dtype
.....: return [dtype, [subdtypes(dt) for dt in subs]]
.....:
All numpy dtypes are subclasses of numpy.generic:
In [307]: subdtypes(np.generic)
Out[307]:
[numpy.generic,
[[numpy.number,
[[numpy.integer,
[[numpy.signedinteger,
[numpy.int8,
numpy.int16,
numpy.int32,
numpy.int32,
numpy.int64,
numpy.timedelta64]],
[numpy.unsignedinteger,
[numpy.uint8,
numpy.uint16,
numpy.uint32,
numpy.uint32,
numpy.uint64]]]],
[numpy.inexact,
[[numpy.floating,
[numpy.float16, numpy.float32, numpy.float64, numpy.float96]],
[numpy.complexfloating,
[numpy.complex64, numpy.complex128, numpy.complex192]]]]]],
[numpy.flexible,
[[numpy.character, [numpy.string_, numpy.unicode_]],
[numpy.void, [numpy.core.records.record]]]],
numpy.bool_,
numpy.datetime64,
numpy.object_]]
Note
Pandas also defines an additional category dtype, which is not integrated into the normal numpy hierarchy and wont show up with the above function.
Note
The include and exclude parameters must be non-string sequences.